RabbitMQ分布式架构模式
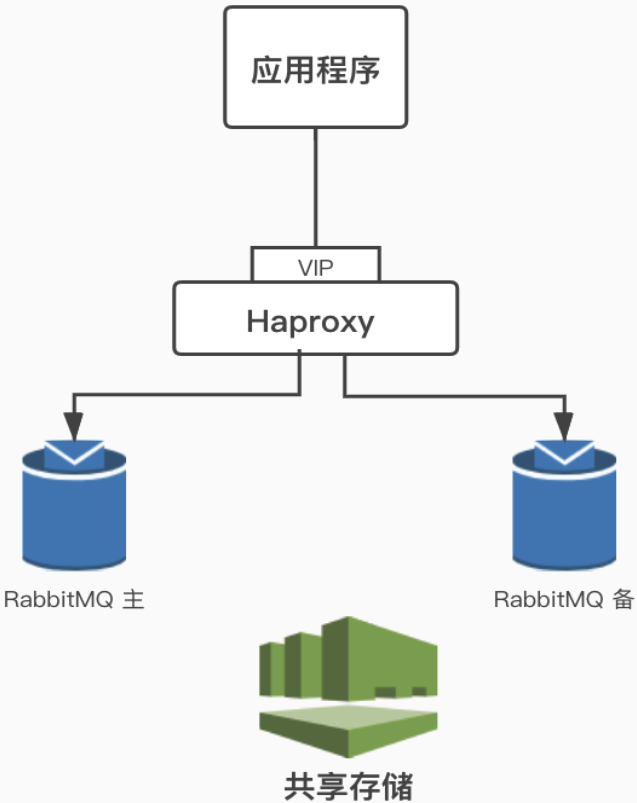
主备模式
也叫Warren(兔子窝)模式,同一时刻只有一个节点在工作(备份节点不能读写),当主节点发生故障后会将请求切换到备份节点上(主恢复后成为备份节点)。需要借助HAProxy之类的(VIP模式)负载均衡器来做健康检查和主备切换,底层需要借助共享存储(如SAN设备)。
这不是RabbitMQ官方或者开源社区推荐方案,适用于访问压力不是特别大但是又有高可用架构需求(故障切换)的中小规模的系统来使用。首先有一个节点闲置,本身就是资源浪费,其次共享存储往往需要借助硬件存储,或者分布式文件系统。
Shovel铲子模式
Shovel是一个插件,用于实现跨机房数据复制,或者数据迁移,故障转移与恢复等。
如下图,用户下单的消费先是投递在Goleta Broker实例中,当Goleta实例达到触发条件后(例如:消息堆积数达到阈值)会将消息放到Goleta实例的backup_orders备份队列中,并通过Shovel插件从Goleta的backup_orders队列中将消息拉取到Carpinteria实例存储。


使用Shovel插件后,模型变成了近端同步确认,远端异步确认的方式。
此模式支持WAN传输,并且broker实例的RabbitMQ、Erlang版本不要求完全一致。
Shovel的配置分静态模式(修改RabbitMQ配置)和动态模式(在控制台直接部署,重启后失效)。
RabbitMQ集群
RabbitMQ集群允许消费者和生产者在RabbitMQ单个节点崩溃的情况下继续运行,并可以通过添加更多的节点来线性扩展消息通信的吞吐量。当失去一个RabbitMQ节点时,客户端能够重新连接到集群中的任何其他节点并继续生产和消费。
RabbitMQ集群中的所有节点都会备份所有的元数据信息,包括:
- 队列元数据:队列的名称及属性
- 交换器:交换器的名称及属性
- 绑定关系元数据:交换器与队列或者交换器与交换器之间的绑定关系
- vhost元数据:为vhost内的队列、交换器和绑定提供命名空间及安全属性
基于存储空间和性能的考虑,RabbitMQ集群中的各节点存储的消息是不同的(有点儿类似分片集群,各节点数据并不是全量对等的),各节点之间同步备份的仅仅是上述元数据以及Queue Owner(队列所有者,就是实际创建Queue并保存消息数据的节点)的指针。当集群中某个节点崩溃后,该节点的队列进程和关联的绑定都会消失,关联的消费者也会丢失订阅信息,节点恢复后(前提是消息有持久化)消息可以重新被消费。虽然消息本身也会持久化,但如果节点磁盘存储设备发生故障那同样会导致消息丢失。
总的来说,该集群模式只能保证集群中的某个Node挂掉后应用程序还可以切换到其他Node上继续地发送和消费消息,但并无法保证原有的消息不丢失,所以并不是一个真正意义的高可用集群。

这是RabbitMQ内置的集群模式,Erlang语言天生具备分布式特性,所以不需要借助类似Zookeeper之类的组件来实现集群(集群节点间使用cookie来进行通信验证,所有节点都必须使用相同的 .erlang.cookie 文件内容),不同节点的Erlang、RabbitMQ版本必须一致。
镜像队列模式
前面我们讲了,RabbitMQ内置的集群模式有丢失消息的风险,“镜像队列”可以看成是对内置默认集群模式的一种高可用架构的补充。可以将队列镜像(同步)到集群中的其他broker上,相当于是多副本冗余。如果集群中的一个节点失效,队列能自动地切换到集群中的另一个镜像节点上以保证服务的可用性,而且消息不丢失。
在RabbitMQ镜像队列中所谓的master和slave都仅仅是针对某个queue而言的,而不是node。一个queue第一次创建所在的节点是它的master节点,其他节点为slave节点。如果master由于某种原因失效,最先加入的slave会被提升为新的master。
无论客户端请求到达master还是slave,最终数据都是从master节点获取。当请求到达master节点时,master节点直接将消息返回给client,同时master节点会通过GM(Guaranteed Multicast)协议将queue的最新状态广播到slave节点。GM保证了广播消息的原子性,即要么都更新要么都不更新。当请求到达slave节点时,slave节点需要将请求先重定向到master节点,master节点将消息返回给client,同时master节点会通过GM协议将queue的最新状态广播到slave节点。
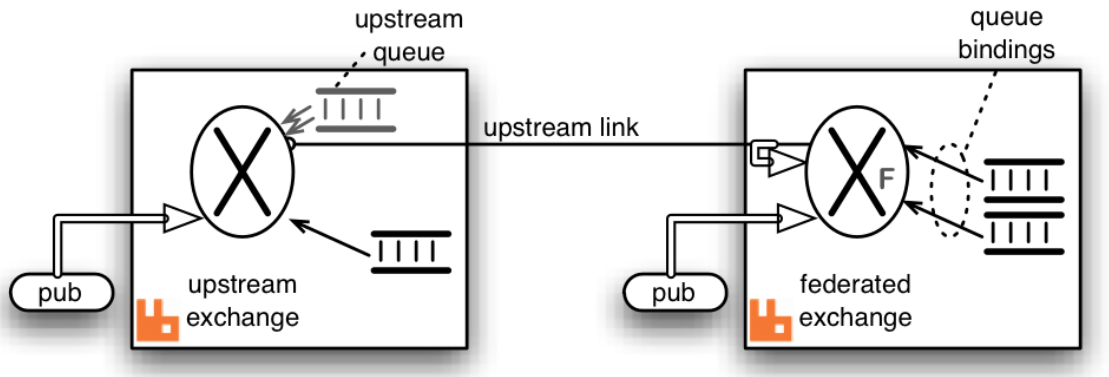
Federation联邦模式
Federation和Shovel类似,也是一个实现跨集群、节点消息同步的插件。支持联邦交换器、联邦队列(作用在不同级别)。
Federation插件允许你配置一个exchanges federation或者queues federation。
一个exchange/queues federation允许你从一个或者多个upstream接收信息,就是远程的exchange/queues。
无论是Federation还是Shovel都只是解决消息数据传输的问题(当然插件自身可能会一些应用层的优化),跨机房跨城市的这种网络延迟问题是客观存在的,不是简单的通过什么插件可以解决的,一般需要借助昂贵的专线。
单机多实例部署
在单个Linux虚拟机上运行多个RabbitMQ实例:
- 多个RabbitMQ使用的端口号不能冲突
- 多个RabbitMQ使用的磁盘存储路径不能冲突
- 多个RabbitMQ的配置文件也不能冲突
在单个Linux虚拟机上运行多个RabbitMQ实例,涉及到RabbitMQ虚拟主机的名称不能重复,每个RabbitMQ使用的端口不能重复。
RABBITMQ_NODE_PORT用于设置RabbitMQ的服务发现,对外发布的其他端口在这个端口基础上计算得来。
| 端口号 | 说明 |
| 4369 | epmd,RabbitMQ节点和CLI工具使用的对等发现服务 |
| 5672、5671 | 分别为不带TLS和带TLS的AMQP 0-9-1和1.0客户端使用 |
| 25672 | 用于节点间和CLI工具通信(Erlang分发服务器端口),并从动态范围分配(默认情况下限制为单个端口,计算为AMQP端口+ 20000)。一般这些端口不应暴露出去 |
| 35672-35682 | 由CLI工具(Erlang分发客户端端口)用于与节点进行通信,并从动态范围(计算为服务器分发端口+ 10000通过服务器分发端口+ 10010)分配 |
| 15672 | HTTP API客户端,管理UI和Rabbitmqadmin(仅在启用了管理插件的情况下) |
| 61613、61614 | 不带TLS和带TLS的STOMP客户端(仅在启用STOMP插件的情况下) |
| 1883、8883 | 如果启用了MQTT插件,则不带TLS和具有TLS的MQTT客户端 |
| 15674 | STOMP-over-WebSockets客户端(仅在启用了Web STOMP插件的情况下) |
| 15675 | MQTT-over-WebSockets客户端(仅在启用Web MQTT插件的情况下) |
| 15692 | Prometheus指标(仅在启用Prometheus插件的情况下) |
RABBITMQ_NODENAME 用于设置RabbitMQ节点名称, @前缀是用户名, @后缀是RabbitMQ所在的Linux主机的 hostname 。
数据存储目录:

日志数据存储目录:
RabbitMQ使用的环境变量:
| 环境变量 | 解释说明 |
| RABBITMQ_NODE_IP_ADDRESS | 将RabbitMQ绑定到一个网络接口。 如果要绑定多个网络接口,可以在配置文件中配置。 默认值:空字串。表示绑定到所有的网络接口 |
| RABBITMQ_NODE_PORT | 默认值:5672 |
| RABBITMQ_DIST_PORT | RabbitMQ节点之间通信以及节点和CLI工具通信用到的端口。 如果在配置文件中配置了kernel.inet_dist_listen_min 或者kernel.inet_dist_listen_max,则忽略该配置。 默认值:$RABBITMQ_NODE_PORT + 20000 |
| ERL_EPMD_ADDRESS | epmd 使用的网络接口, epmd 用于节点之间以及节点和CLI之间的通信。 默认值:所有网络接口,包括和IPv4 |
| ERL_EPMD_PORT | epmd 使用的端口。 默认值:4369 |
| RABBITMQ_DISTRIBUTION_BUFFER_SIZE | 节点之间通信连接使用的发送数据缓冲区大小限制, 单位是KB。推荐使用小于64MB的值。 默认值:128000 |
| RABBITMQ_IO_THREAD_POOL_SIZE | Erlang运行时的 I/O 用到的线程数。不推荐小于32的值。 默认值:128(Linux),64(Windows) |
| RABBITMQ_NODENAME | RabbitMQ的节点名称。对于Erlang节点和机器,此名称应该唯一。 通过设置此值,可以在一台机器上多个RabbitMQ节点。 默认值:rabbit@$HOSTNAME(Unix-like),rabbit@%COMPUTERNAME%(Windows) |
| RABBITMQ_CONFIG_FILE | RabbitMQ主要配置文件的路径。例如 /etc/rabbitmq/rabbitmq.conf 或 者 /data/configuration/rabbitmq.conf 是新格式的配置文件。 如果是老格式的配置文件,扩展名是 .config 或者不写。 默认值: 对于Unix: $RABBITMQ_HOME/etc/rabbitmq/rabbitmq Debian: /etc/rabbitmq/rabbitmq RPM: /etc/rabbitmq/rabbitmq MacOS(Homebrew):${install_prefix}/etc/rabbitmq/rabbitmq , Homebrew的前缀通常是: /usr/local/ Windo%APPDATA%\RabbitMQ\rabbitmq |
| RABBITMQ_ADVANCED_CONFIG_FILE | RabbitMQ带 .config 的高级配置文件路径(基于Erlang配置)。例 如, /data/rabbitmq/advanced.config 。 默认值: Unix: $RABBITMQ_HOME/etc/rabbitmq/advanced Debian: /etc/rabbitmq/advanced RPM: /etc/rabbitmq/advanced MacOS(Homebrew): ${install_prefix}/etc/rabbitmq/advanced , 其中Homebrew前缀通常是 /etc/local/ Windows: %APPDATA%\RabbitMQ\advanced |
| RABBITMQ_CONF_ENV_FILE | 包含了环境变量定义的文件的目录(不使用 RABBITMQ_ 前缀)。 Windows上的文件名称与其他操作系 同。 默认值: UNIX: $RABBITMQ_HOME/etc/rabbitmq/rabbitmq-env.conf Ubuntu和Debian: /etc/rabbitmq/rabbitmq-env.conf RPM: /etc/rabbitmq/rabbitmq-env.conf Mac (Homebrew): ${install_prefix}/etc/rabbitmq/rabbitmq-env.conf ,Homebrew的前缀一般是 /usr/local Windows: %APPDATA%\RabbitMQ\rabbitmq-env-conf.bat |
| RABBITMQ_MNESIA_BASE | 包含了RabbitMQ服务器的节点数据库、消息存储以及 集群状态文件子目录的根目录。除非显式设置了RABBITMQ_MNESIA_DIR 的值。需要确保RabbitMQ用户 在该目录拥有读、写和创建文件以及子目录的该变量一般不要覆盖。一般覆盖 RABBITMQ_MNESIA_DIR 变量。 默认值: Unix: $RABBITMQ_HOME/var/lib/rabbitmq/mnesia Ubuntu和Debian: /var/lib/rabbitmq/mnesia/ RPM: /var/lib/rabbitmq/plugins MacOS(Homebrew):${install_prefix}/var/lib/rabbitmq/mnesia 其中Homebrew的前缀一般是 /usr/local Windows: %APPDATA%\RabbitMQ |
| RABBITMQ_MNESIA_DIR | RabbitMQ节点存储数据的目录。该目录中包含了数据库、 消息存储、集群成员信息以及节点其他的持状态。 默认值: 通用UNIX包: $RABBITMQ_MNESIA_BASE/$RABBITMQ_NODENAME Ubuntu和Debia:$RABBITMQ_MNESIA_BASE/$RABBITMQ_NODENAME RPM: $RABBITMQ_MNESIA_BASE/$RABBITMQ_NO MacOS (Homebrew):${install_prefix}/var/lib/rabbitmq/mnesia/$RABBITMQ_NODENAME , Homebrew的前缀一般是 /usr/local Windows: %APPDATA%\RabbitMQ\$RABBITMQ_NODENAME |
| RABBITMQ_PLUGINS_DIR | 存放插件压缩文件的目录。RabbitMQ从此目录解压插件。 跟PATH变量语法类似,多个路径之间使用统的分隔符分隔 (Unix是 : ,Windows是';')。插件可以安装到该变量指定的任何目录。 路径不要有 符。 默认值: 通用UNIX包: $RABBITMQ_HOME/plugins Ubuntu和Debian包: /var/lib/rabbitmq/plugins RPM: /var/lib/rabbitmq/plugins MacOS (Homebrew):${install_prefix}/Cellar/rabbitmq/${version}/plugins Homebrew的前缀一般是 /usr/l Windows: %RABBITMQ_HOME%\plugins |
| RABBITMQ_PLUGINS_EXPAND_DIR | 节点解压插件的目录,并将该目录添加到代码路径。该路径不要包含特殊字符。 默认值: UNIX:$RABBITMQ_MNESIA_BASE/$RABBITMQ_NODENAME-plugins-expand Ubuntu和Debian packages:$RABBITMQ_MNESIA_BASE/$RABBITMQ_NODENAME-plugins-expand RPM:$RABBITMQ_MNESIA_BASE/$RABBITMQ_NODENAME-plugins-expand MacOS (Homebrew):${install_prefix}/var/lib/rabbitmq/mnesia/$RABBITMQ_NODENAME-plugins-expand Windows:%APPDATA%\RabbitMQ\$RABBITMQ_NODENAME-plugins-expand |
| RABBITMQ_USE_LONGNAME | 当设置为 true 的时候,RabbitMQ会使用全限定主机名标记节点。 在使用全限定域名的环境中使用。重置节点, 不能在全限定主机名和短名之间切换。 默认值: false |
| RABBITMQ_SERVER_CODE_PATH | 当启用运行时的时候指定的外部代码路径(目录)。 当节点启动的时候,这个是值传给 erl 的命令行默认值:(none) |
| RABBITMQ_CTL_ERL_ARGS | 当调用 rabbitmqctl 的时候传给 erl 的命令行参数。 可以给Erlang设置使用端口的范围: -kernel inet_dist_listen_min 35672 -kernel inet_dist_listen_max 35680 默认值:(none) |
| RABBITMQ_SERVER_ERL_ARGS | 当调用RabbitMQ服务器的时候 erl 的标准命令行参数。 仅用于测试目的。使用该环境变量会覆盖默认。默认值: Unix*: +P 1048576 +t 5000000 + stbt db +zdbbl 128000 Windows:没有 |
| RABBITMQ_SERVER_ADDITIONAL_ERL_ARGS | 调用RabbitMQ服务器的时候传递给 erl 命令的额外参数。 该变量指定的变量追加到默认参数列表( RABBITMQ_SERVER_ERL_ARGS )。 默认值: Unix*: 没有 Windows: 没有 |
| RABBITMQ_SERVER_START_ARGS | 调用RabbitMQ服务器的时候传给 erl 命令的额外参数。该变量不覆盖 RABBITMQ_SERVER_ERL_ARGS。默认值:没有 |
| RABBITMQ_ENABLED_PLUGINS_FILE | 用于指定 enabled_plugins 文件所在的位置。 默认: /etc/rabbitmq/enabled_plugins |
方式一:
export RABBITMQ_NODE_PORT=5672
export RABBITMQ_NODENAME=rabbit2
rabbitmq-server
export RABBITMQ_NODE_PORT=5673
export RABBITMQ_NODENAME=rabbit3
rabbitmq-server
export RABBITMQ_NODE_PORT=5674
export RABBITMQ_NODENAME=rabbit4
rabbitmq-server方式二:
RABBITMQ_NODE_PORT=5672 RABBITMQ_NODENAME=rabbit2 rabbitmq-server
RABBITMQ_NODE_PORT=5673 RABBITMQ_NODENAME=rabbit3 rabbitmq-server
RABBITMQ_NODE_PORT=5674 RABBITMQ_NODENAME=rabbit4 rabbitmq-server启动web控制台的管理插件:
rabbitmq-plugins enable rabbitmq_management RabbitMQ从3.3.0开始禁止使用guest/guest权限通过除localhost外的访问。如果想使用guest/guest通过远程机器访问,需要在RabbitMQ配置文件中设置loopback_users为[],当然也可以自己创建用户。
vim /etc/rabbitmq/rabbitmq.conf 
需要注意的是,如果要使用自定义位置的配置文件,需要目录属于RabbitMQ组。
默认配置文件的位置:/etc/rabbitmq/rabbitmq.conf。
我们在/opt/rabbitconf中创建三个配置文件:rabbit1.conf,rabbit2.conf,rabbit3.conf,其中注明三个RabbitMQ实例使用的rabbitmq_management插件使用的端口号,以及开通guest远程登录系统的权限:
| 文件路径 | 内容 |
| /opt/rabbitmqconf/rabbit1.conf | loopback_users.guest=false management.tcp.port=6001 |
| /opt/rabbitmqconf/rabbit2.conf | loopback_users.guest=false management.tcp.port=6002 |
| /opt/rabbitmqconf/rabbit3.conf | loopback_users.guest=false management.tcp.port=6003 |
启动命令:
| 节点名称 | 命令 |
| rabbit1 | RABBITMQ_NODENAME=rabbit1 RABBITMQ_NODE_PORT=5001 RABBITMQ_CONFIG_FILE=/opt/rabbitconf/rabbit1.conf rabbitmq-server |
| rabbit2 | RABBITMQ_NODENAME=rabbit1 RABBITMQ_NODE_PORT=5002 RABBITMQ_CONFIG_FILE=/opt/rabbitconf/rabbit2.conf rabbitmq-server |
| rabbit3 | RABBITMQ_NODENAME=rabbit1 RABBITMQ_NODE_PORT=5003 RABBITMQ_CONFIG_FILE=/opt/rabbitconf/rabbit3.conf rabbitmq-server |
停止命令:
| 节点名称 | 命令 |
| rabbit1 | rabbitmqctl -n rabbit1 stop |
| rabbit2 | rabbitmqctl -n rabbit2 stop |
| rabbit3 | rabbitmqctl -n rabbit3 stop |
集群管理
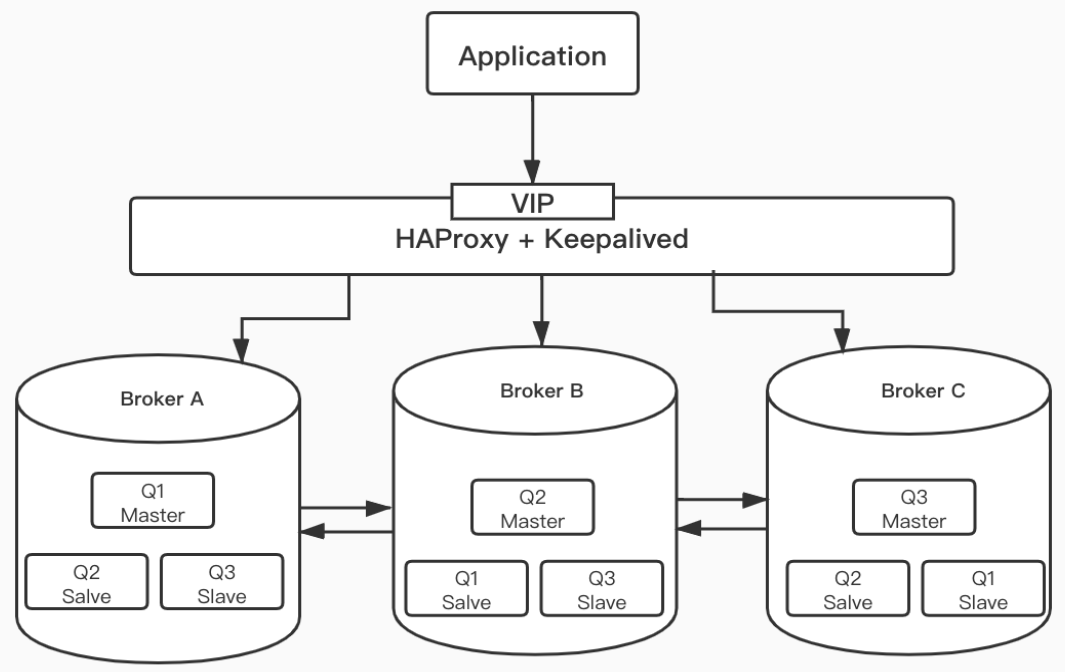
前面我们讲了几种RabbitMQ分布式/集群架构的模式,下面我们结合Rabbit集群+ 镜像队列,并借助HAProxy 实现负载均衡的集群。
- 在node2、node3、node4三台Linux虚拟机中安装RabbitMQ
- 从node2拷贝.erlang.cookie到node3、node4的相应目录
如果没有该文件,手动创建 /var/lib/rabbitmq/.erlang.cookie ,生成Cookie字符串,或者启动一次RabbitMQ自动生成该文件。生产中推荐使用第三方工具生成。
我们首先在node2上启动单机版RabbitMQ,以生成Cookie文件:
systemctl start rabbitmq-server 开始准备同步 .erlang.cookie 文件。RabbitMQ的集群依赖Erlang的分布式特性,需要保持Erlang Cookie一致才能实现集群节点的认证和通信,我们直接使用scp命令从node1远程传输。
scp /var/lib/rabbitmq/.erlang.cookie root@node3:/var/lib/rabbitmq/
scp /var/lib/rabbitmq/.erlang.cookie root@node4:/var/lib/rabbitmq/修改node3和node4上该文件的所有者为rabbitmq:rabbitmq:
chown rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie 注意.erlang.cookie文件权限为400:
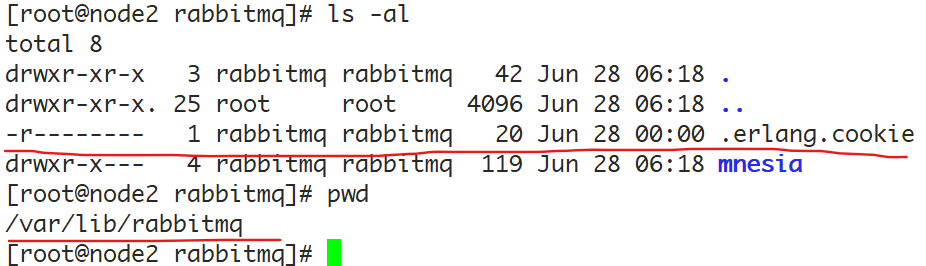
- 使用下述命令启动node3和node4上的RabbitMQ:
systemctl start rabbitmq-server - 将node3和node4这两个节点加入到集群中
分别执行如下命令:
# 停止Erlang VM上运行的RabbitMQ应用,保持Erlang VM的运行
rabbitmqctl stop_app
# 移除当前RabbitMQ虚拟主机中的所有数据:重置
rabbitmqctl reset
# 将当前RabbitMQ的主机加入到rabbit@node2这个虚拟主机的集群中。一个节点也是集群。
rabbitmqctl join_cluster rabbit@node2
# 启动当前Erlang VM上的RabbitMQ应用
rabbitmqctl start_apprabbit@node2 表示RabbitMQ节点名称,默认前缀就是 rabbit , @ 之后是当前虚拟主机所在的物理主机 hostname 。
join_cluster默认是使用disk模式,后面可以加入参数--ram启用内存模式。
移出集群节点使用:
# 将虚拟主机(RabbitMQ的节点)rabbit@node3从集群中移除,但是rabbit@node3还保留集群信
息
# 还是会尝试加入集群,但是会被拒绝。可以重置rabbit@node3节点。
rabbitmqctl forget_cluster_node rabbit@node3#修改集群名称(任意节点执行都可以)
rabbitmqctl set_cluster_name
#查看集群状态(任意节点执行都可以)
rabbitmqctl cluster_status- 在三个RabbitMQ节点上的任意一个添加用户,设置用户权限,设置用户标签,即可:
rabbitmqctl add_user root 123456
rabbitmqctl set_permissions --vhost "/" root ".*" ".*" ".*"
rabbitmqctl set_user_tags --vhost "/" root administrator可以到Web控制台查看集群信息,如果要看到所有RabbitMQ节点上的运行情况,都需要启rabbitmq_management 插件。

RabbitMQ镜像集群配置
RabbitMQ中队列的内容是保存在单个节点本地的(声明队列的节点)。跟交换器和绑定不同,它们是对于集群中所有节点的。如此,则队列内容存在单点故障,解决方式之一就是使用镜像队列。在多个节点上拷贝队列的副本。
每个镜像队列包含一个master,若干个镜像。
master存在于称为master的节点上。
所有的操作都是首先对master执行,之后广播到镜像。
这涉及排队发布,向消费者传递消息,跟踪来自消费者的确认等。
镜像意味着集群,不应该WAN使用。
发布到队列的消息会拷贝到该队列所有的镜像。消费者连接到master,当消费者对消息确认之后,镜像删除master确认的消息。
队列的镜像提供了高可用,但是没有负载均衡。
HTTP API和CLI工具中队列对象的字段原来使用的是slave代表secondaries,现在该字段的存在仅是为了向后兼容,后续版本会移除。
可以使用策略随时更改队列的类型,可以首先创建一个非镜像队列,然后使用策略将其配置为镜像队列或者反过来。非镜像队列没有额外的基础设施,因此可以提供更高的吞吐率。
master选举策略:
- 最长的运行镜像升级为主镜像,前提是假定它与主镜像完全同步。如果没有与主服务器同步的镜像,则仅存在于主服务器上的消息将丢失
- 镜像认为所有以前的消费者都已突然断开连接。它重新排队已传递给客户端但正在等待确认的所有消息。这包括客户端已为其发出确认的消息,例如,确认是在到达节点托管队列主节点之前在线路上丢失了,还是在从主节点广播到镜像时丢失了。在这两种情况下,新的主服务器都别无选择,只能重新排队它尚未收到确认的所有消息
- 队列故障转移时请求通知的消费者将收到取消通知。当镜像队列发生了master的故障转移,系统就不知道向哪些消费者发送了哪些消息。已经发送的等待确认的消息会重新排队
- 重新排队的结果是,从队列重新使用的客户端必须意识到,他们很可能随后会收到已经收到的消息
- 当所选镜像成为主镜像时,在此期间发布到镜像队列的消息将不会丢失(除非在提升的节点上发生后续故障)。发布到承载队列镜像的节点的消息将路由到队列主服务器,然后复制到所有镜像。如果主服务器发生故障,则消息将继续发送到镜像,并在完成向主服务器的镜像升级后将其添加到队列中
- 即使主服务器(或任何镜像)在正在发布的消息与发布者收到的确认之间失败,由客户端使用发布者确认发布的消息仍将得到确认。从发布者的角度来看,发布到镜像队列与发布到非镜像队列没有什么不同
给队列添加镜像要慎重。
| ha-mode | ha-params | 结果 |
| exactly | count | 设置集群中队列副本的个数(镜像+master)。1表示一个副本;也就是master。如果master不可用,行为依赖于队列的持久化机制。2表示1个master和1个镜像。如果master不可用,则根据镜像推举策略从镜像中选出一个做master。如果节点数量比镜像副本个数少,则镜像覆盖 到所有节点。如果count个数少于集群节点个数,则在一个镜像宕机后,会在其他节点创建出来一个镜像。将“exactly”模式与“ha-promote-on-shutdown”: “ always”一起使用可能很危险,因为队列可以在整个集群中迁移并在关闭时变得不同步 |
| all | (none) | 镜像覆盖到集群中的所有节点。当添加一个新的节点,队列就会复制过去。这个配置很保守。一般推荐N/2+1个节点。在集群所有节点拷贝镜像会给集群所有节点施加额外的负载,包括网络IO,磁盘IO和磁盘空间使用 |
| nodes | node ames | 在指定node name的节点上复制镜像。node name就是在rabbitmqctl cluster_status命令输出中的node name。如果有不属于集群的节点名称,它不报错。如果指定的节点都不在线,则仅在客户端连接到的声明镜像的节点上创建镜像 |
接下来,启用镜像队列:
# 对/节点配置镜像队列,使用全局复制
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
# 配置过半(N/2 + 1)复制镜像队列
rabbitmqctl set_policy ha-halfmore "queueA" '{"ha-mode":"exactly", "ha-
params":2}'
# 指定优先级,数字越大,优先级越高
rabbitmqctl set_policy --priority 1 ha-all "^" '{"ha-mode":"all"}'在任意一个节点上面执行即可。默认是将所有的队列都设置为镜像队列,在消息会在不同节点之间复制,各节点的状态保持一致。
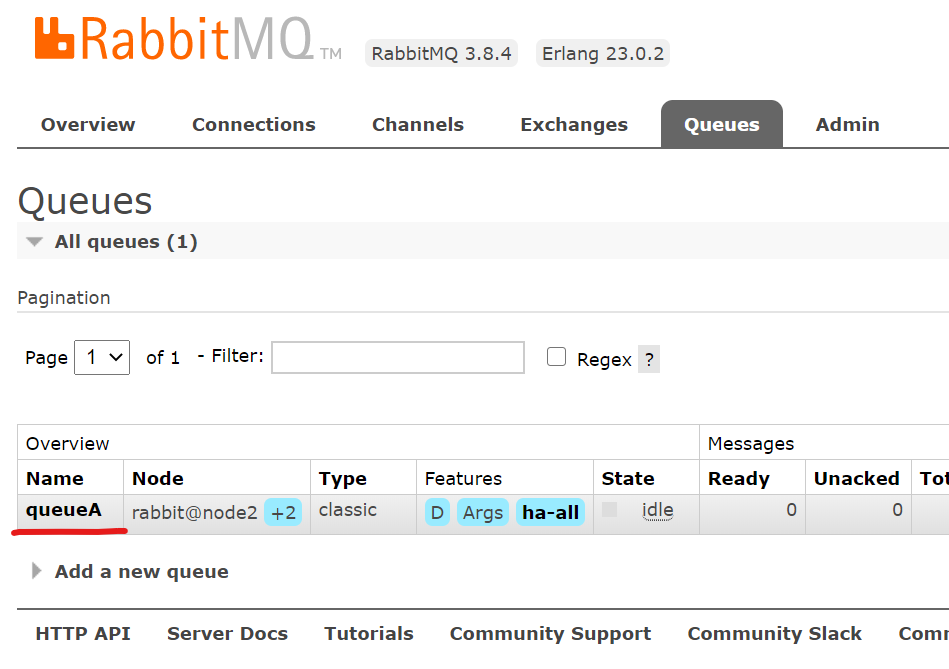
点击上图中的queueA,查看该队列的细节:
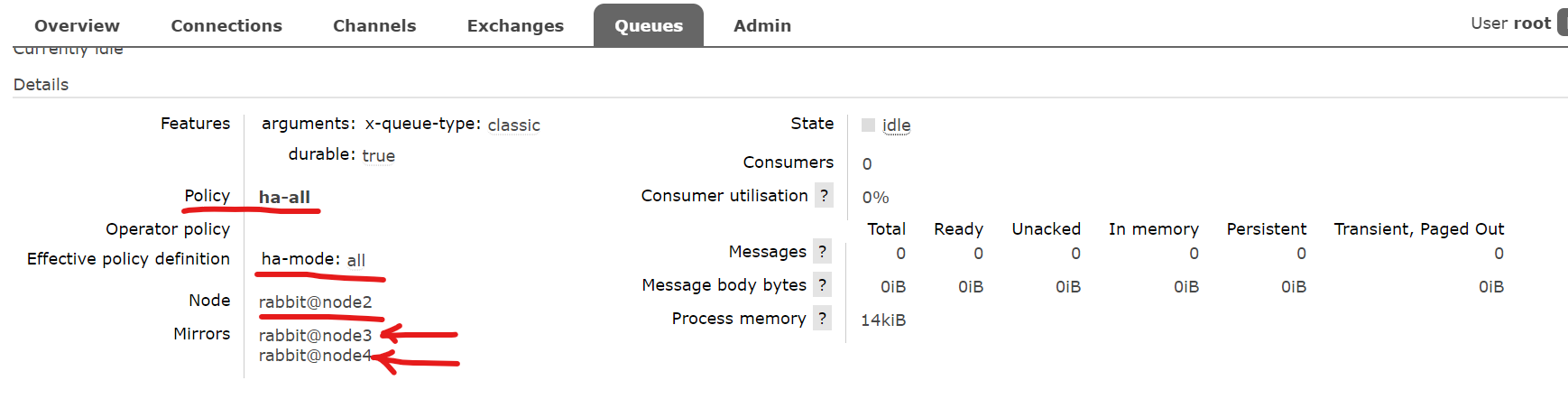
其他细节可以查看官方文档:https://www.rabbitmq.com/ha.html。
负载均衡-HAProxy
将客户端的连接和操作的压力分散到集群中的不同节点,防止单个或几台服务器压力过大成为访问的瓶颈,甚至宕机。
HAProxy是一款开源免费,并提供高可用性、负载均衡以及基于TCP和HTTP协议的代理软件,可以支持四层、七层负载均衡,经过测试单节点可以支持10W左右并发连接。
LVS是工作在内核模式(IPVS),支持四层负载均衡,实测可以支撑百万并发连接。
Nginx支持七层的负载均衡(后期的版本也支持四层了),是一款高性能的反向代理软件和Web服务器,可以支持单机3W以上的并发连接。
这里我们使用HAProxy来做RabbitMQ的负载均衡,通过暴露VIP给上游的应用程序直接连接,上游应用程序不感知底层的RabbitMQ的实例节点信息。
我们可以在官网或者附件中下载安装包。
yum install gcc -y
tar -zxf haproxy-2.1.0.tar.gz
cd haproxy-2.1.0
make TARGET=linux-glibc
make install
mkdir /etc/haproxy
# 赋权
groupadd -r -g 149 haproxy
# 添加用户
useradd -g haproxy -r -s /sbin/nologin -u 149 haproxy
# 创建haproxy配置文件
touch /etc/haproxy/haproxy.cfg如果你觉得编译安装很麻烦,你可以简单的
yum -y install haproxy 如果使用yum安装的,那么haproxy默认在/usr/sbin/haproxy,且会自动创建配置文件/etc/haproxy/haproxy.cfg。
配置HAProxy
vim /etc/haproxy/haproxy.cfg 配置文件都做了详细注释,如下:
global
log 127.0.0.1 local0 info
# 服务器最大并发连接数;如果请求的连接数高于此值,将其放入请求队列,等待其它连接被释
放;
maxconn 5120
# chroot /tmp
# 指定用户
uid 149
# 指定组
gid 149
# 让haproxy以守护进程的方式工作于后台,其等同于“-D”选项的功能
# 当然,也可以在命令行中以“-db”选项将其禁用;
daemon
# debug参数
quiet
# 指定启动的haproxy进程的个数,只能用于守护进程模式的haproxy;
# 默认只启动一个进程,
# 鉴于调试困难等多方面的原因,在单进程仅能打开少数文件描述符的场景中才使用多进程模式;
# nbproc 20
nbproc 1
pidfile /var/run/haproxy.pid
defaults
log global
# tcp:实例运行于纯TCP模式,第4层代理模式,在客户端和服务器端之间将建立一个全双工的
连接,
# 且不会对7层报文做任何类型的检查;
# 通常用于SSL、SSH、SMTP等应用;
mode tcp
option tcplog
option dontlognull
retries 3
option redispatch
maxconn 2000
# contimeout 5s
timeout connect 5s
# 客户端空闲超时时间为60秒则HA 发起重连机制
timeout client 60000
# 服务器端链接超时时间为15秒则HA 发起重连机制
timeout server 15000
listen rabbitmq_cluster
# VIP,反向代理到下面定义的三台Real Server
bind 192.168.100.101:5672
# 配置TCP模式
mode tcp
# 简单的轮询
balance roundrobin
# rabbitmq集群节点配置
# inter 每隔五秒对mq集群做健康检查,2次正确证明服务器可用,2次失败证明服务器不可用,
并且配置主备机制
server rabbitmqNode1 192.168.100.102:5672 check inter 5000 rise 2 fall
2
server rabbitmqNode2 192.168.100.103:5672 check inter 5000 rise 2 fall
2
server rabbitmqNode3 192.168.100.104:5672 check inter 5000 rise 2 fall
2
# 配置haproxy web监控,查看统计信息
listen stats
bind 192.168.100.101:9000
mode http
option httplog
# 启用基于程序编译时默认设置的统计报告
stats enable
# 设置haproxy监控地址为http://node1:9000/rabbitmq-stats
stats uri /rabbitmq-stats
# 每5s刷新一次页面
stats refresh 5s启动HAProxy:
haproxy -f /etc/haproxy/haproxy.cfg 关闭:
kill -9 <pid> 检查进程状态,还可以通过访问http://vip:9000/rabbitmq-stats查看状态:

监控
RabbitMQ自带的(Management插件)管理控制台功能比较丰富,不仅提供了Web UI界面,还暴露了很多HTTP API的能力。其中也具备基本的监控能力。此外,自带的命令行工具(例如:rabbitmqctl )也比较强大。
不过这些工具都不具备告警的能力。在实际的生产环境中,我们需要知道负载情况和运行监控状态(例如:系统资源、消息积压情况、节点健康状态等),而且当发生问题后需要触发告警。像传统的监控平台Nagios、Zabbix等均提供了RabbitMQ相关的插件支持。
另外,当前云原生时代最热门的Prometheus监控平台也提供了rabbitmq_exporter,结合Grafana漂亮美观的dashboard(可以自定义,也可以在仓库选择一些现有的)。官网文档地址:https://www.rabbitmq.com/prometheus.html。
以上就是本文的全部内容。欢迎小伙伴们积极留言交流~~~
附件
链接:https://pan.rubinchu.com/share/1462960576488538112
提取码:rboe

文章评论