Elasticsearch是基于Lucene的全文检索引擎,本质也是存储和检索数据。ES中的很多概念与MySQL类似我们可以按照关系型数据库的经验去理解。
核心概念
- 索引(index):类似的数据放在一个索引,非类似的数据放不同索引, 一个索引也可以理解成一个关系型数据库
- 类型(type):代表document属于index中的哪个类别(type)也有一种说法一种type就像是数据库的表,比如dept表,user表。在6.x的版本之后弱化了这个概念,只能创建一个type,7.x之后会逐渐移除这个类型
- 映射(mapping):mapping定义了每个字段的类型等信息。相当于关系型数据库中的表结构。常用数据类型:text、keyword、number、array、range、boolean、date、geo_point、ip、nested、object
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html#_multi_fields_2。
Elasticsearch API介绍
Elasticsearch提供了Rest风格的API,即http请求接口,而且也提供了各种语言的客户端API。
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html。

Elasticsearch支持的语言客户端非常多:https://www.elastic.co/guide/en/elasticsearch/client/index.html。

ElasticSearch没有自带图形化界面,我们可以通过安装ElasticSearch的图形化插件,完成图形化界面的效果,完成索引数据的查看,比如可视化插件Kibana。
安装配置Kibana
Kibana是一个基于Node.js的Elasticsearch索引库数据统计工具,可以利用Elasticsearch的聚合功能,生成各种图表,如柱形图,线状图,饼图等。而且还提供了操作Elasticsearch索引数据的控制台,并且提供了一定的API提示,非常有利于我们学习Elasticsearch的语法。
下载Kibana

Kibana与操作系统的兼容性文档地址:https://www.elastic.co/cn/support/matrix#matrix_os。

安装kibana
root账户下操作:
tar -zxvf kibana-7.3.0-linux-x86_64.tar.gz
mv /root/kibana-7.3.0-linux-x86_64 /usr/kibana/改变Kibana目录拥有者账号:
chown -R estest /usr/kibana/还需要设置访问权限:
chmod -R 777 /usr/kibana/修改配置文件:
vim /usr/kibana/config/kibana.yml
# 修改端口,访问ip,elasticsearch服务器ip
server.port: 5601
server.host: "0.0.0.0"
# The URLs of the Elasticsearch instances to use for all your queries.
elasticsearch.hosts: ["http://192.168.211.136:9200"]配置完成启动:
# 切换用户
su estest
# 前台启动
./bin/kibana(路径:/usr/kibana)
# 后台启动
nohup ./kibana &
# 也可以使用以下脚本启动
#!/usr/bin/env bash
echo 开始启动kibana
cd /rubin/myapps/kibana-7.6.0/bin
rm -rf kibana.log pid.txt
nohup ./kibana > kibana.log 2>&1&
echo $! > pid.txt
echo 启动kibana完成
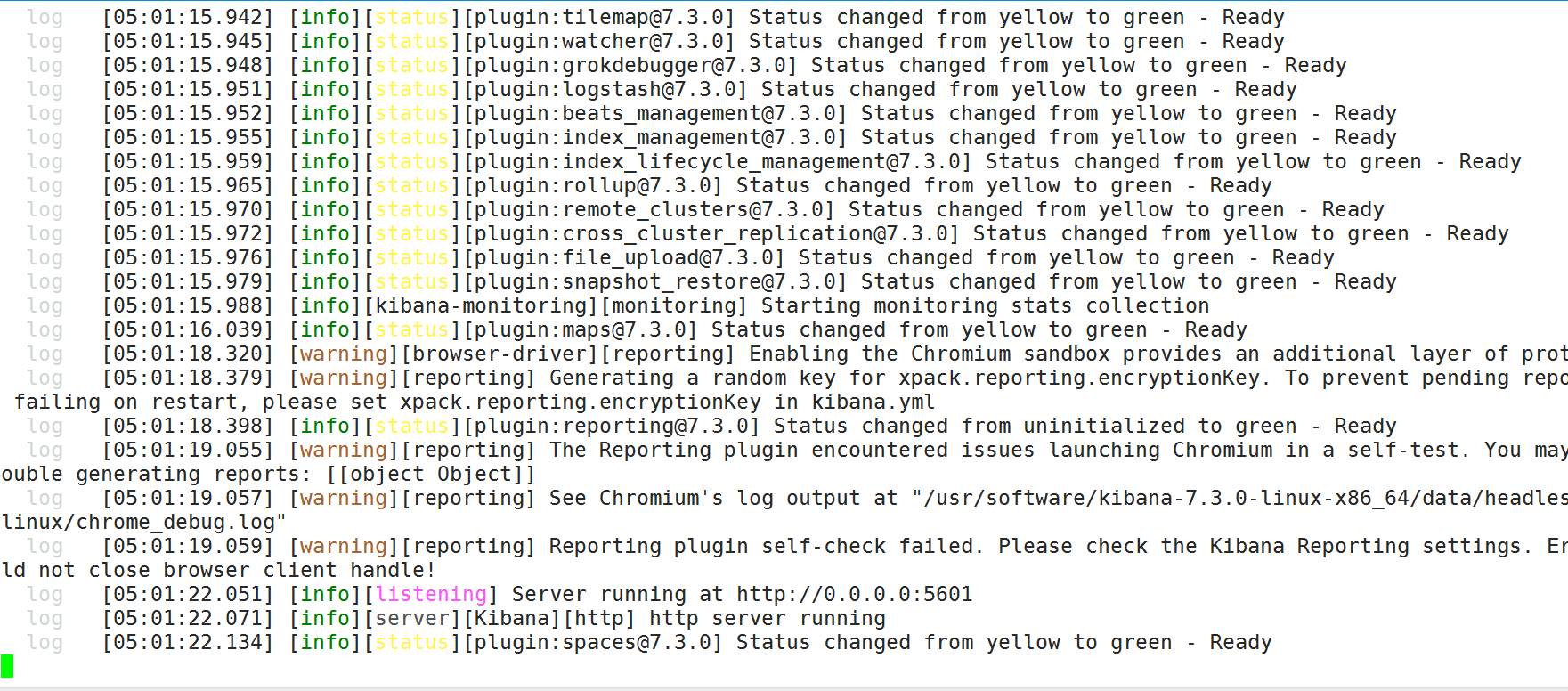
没有error错误启动成功:
访问ip:5601,即可看到安装成功:
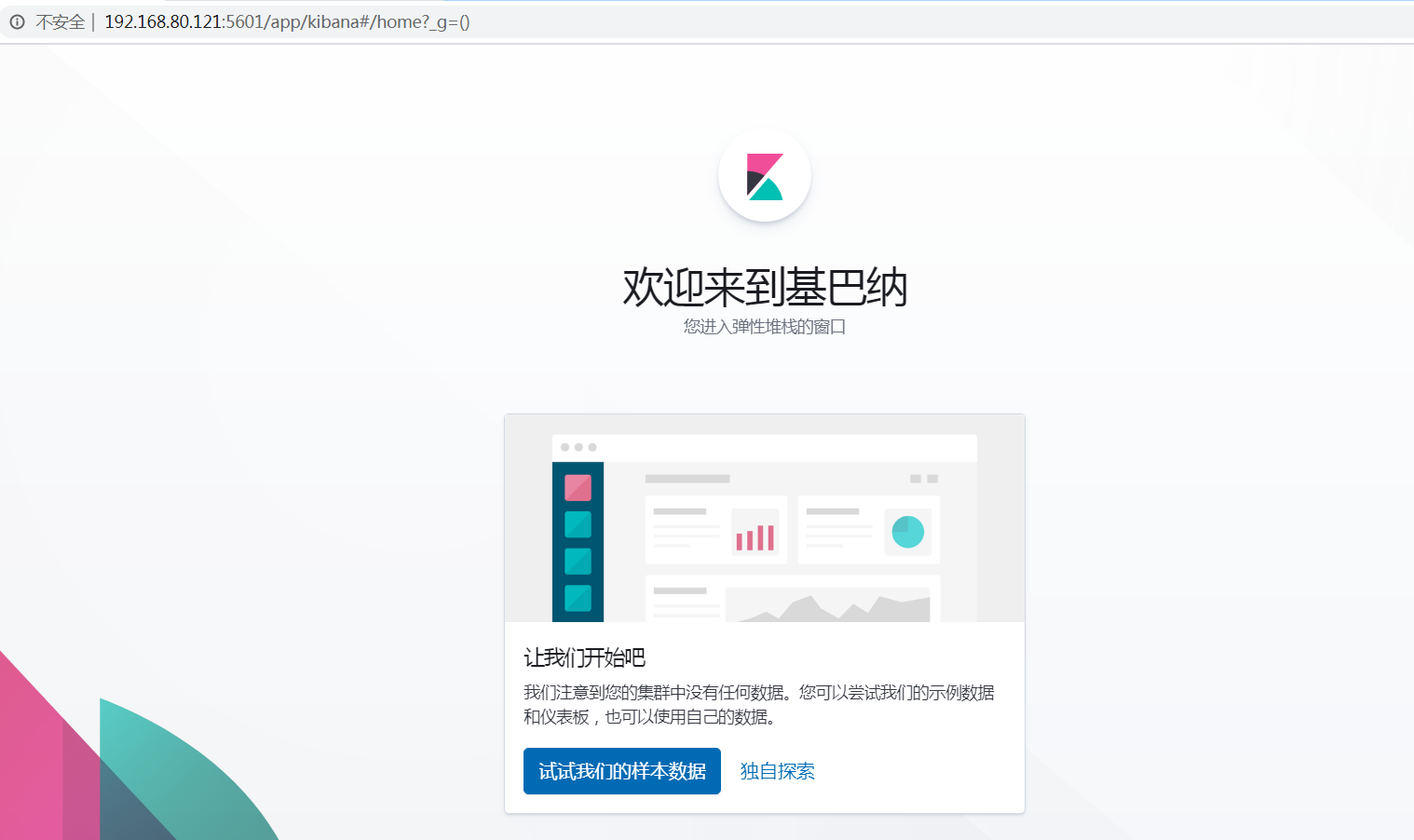
已全部安装完成,然后可以接入数据使用了。
Kidbana使用页面
选择左侧的DevTools菜单,即可进入控制台页面:
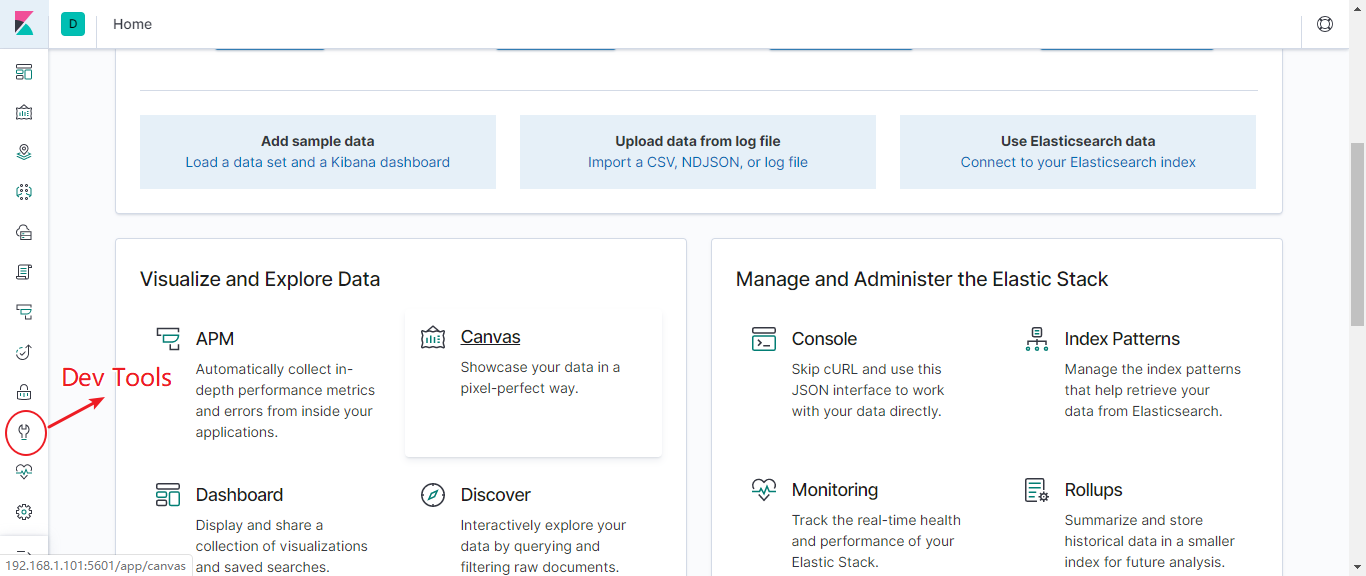
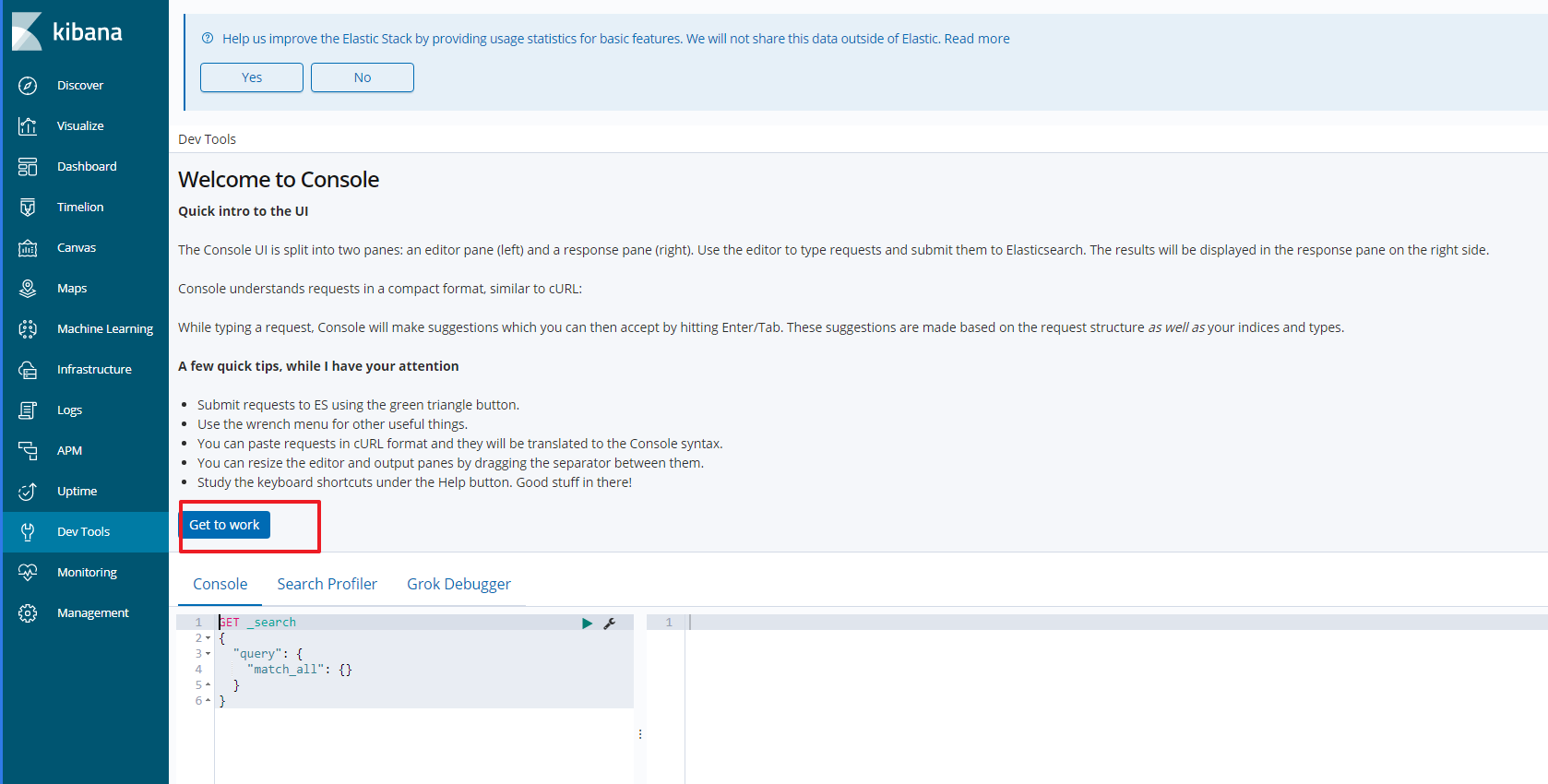
在页面右侧,我们就可以输入请求,访问Elasticsearch了。
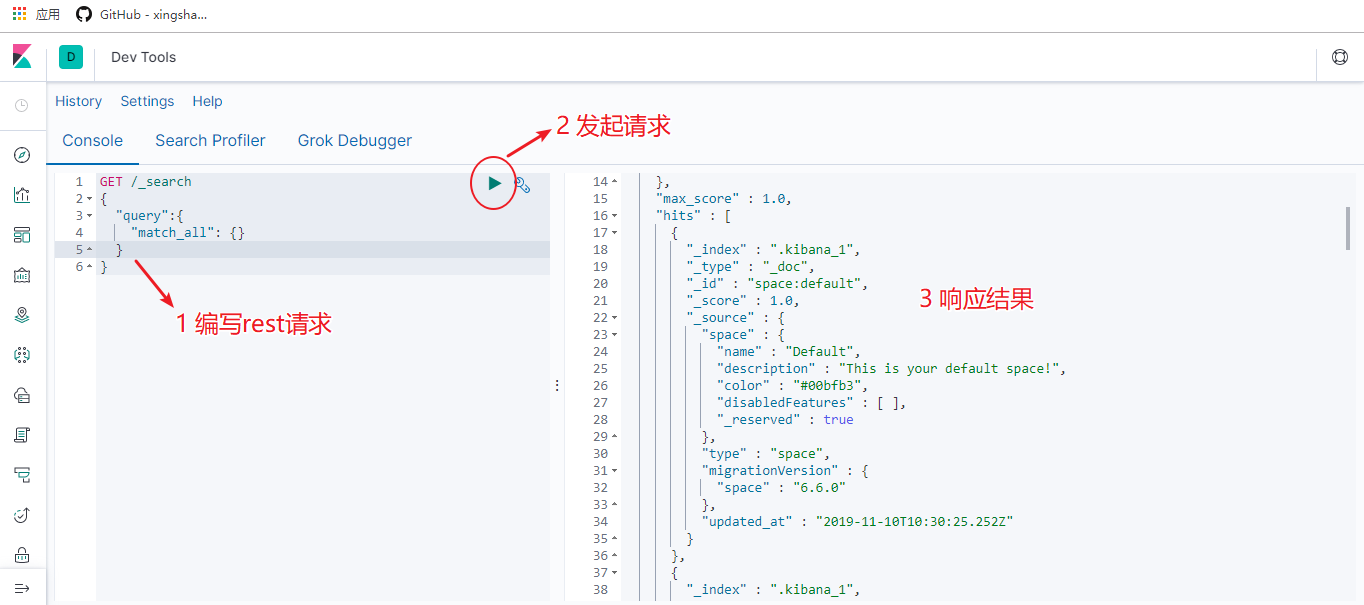
Kibana dev tools快捷键:
ctrl+enter提交请求ctrl+i自动缩进
Elasticsearch集成IK分词器
集成IK分词器
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出 了3个大版本。最初,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为 面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
IK分词器3.0的特性如下:
- 采用了特有的“正向迭代最细粒度切分算法“,具有60万字/秒的高速处理能力
- 采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理
- 支持个人词条的优化的词典存储,更小的内存占用
- 支持用户词典扩展定义
- 针对Lucene全文检索优化的查询分析器IKQueryParser;采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高Lucene检索的命中率
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.3.0。
下载插件并安装(安装方式一)
在elasticsearch的bin目录下执行以下命令,es插件管理器会自动帮我们安装,然后等待安装完成:
usr/elasticsearch/bin/elasticsearch-plugin install
https://github.com/medcl/elasticsearch-analysis-
ik/releases/download/v7.3.0/elasticsearch-analysis-ik-7.3.0.zip下载完成后会提示 Continue with installation? 输入 y 即可完成安装。
重启Elasticsearch和Kibana。
上传安装包安装 (安装方式二)
在Elasticsearch安装目录的plugins目录下新建analysis-ik目录:
#新建analysis-ik文件夹
mkdir analysis-ik
#切换至 analysis-ik文件夹下
cd analysis-ik
#上传资料中的 elasticsearch-analysis-ik-7.3.0.zip
#解压
unzip elasticsearch-analysis-ik-7.3.3.zip
#解压完成后删除zip
rm -rf elasticsearch-analysis-ik-7.3.0.zip重启Elasticsearch和Kibana。
测试案例
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
- ik_max_word (常用):会将文本做最细粒度的拆分
- ik_smart:会做最粗粒度的拆分
我们先不管语法,我们先在Kibana测试一波输入下面的请求:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "南京市长江大桥"
}ik_max_word分词模式运行得到结果:
{
"tokens" : [
{
"token" : "南京市",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "南京",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "市长",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "长江大桥",
"start_offset" : 3,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "长江",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "大桥",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 5
}
]
}POST _analyze
{
"analyzer": "ik_smart",
"text": "南京市长江大桥"
}ik_smart分词模式运行得到结果:
{
"tokens" : [
{
"token" : "南京市",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "长江大桥",
"start_offset" : 3,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 1
}
]
}如果现在假如江大桥是一个人名,是南京市市长,那么上面的分词显然是不合理的,该怎么办?
扩展词典使用
扩展词:就是不想让哪些词被分开,让他们分成一个词。比如上面的江大桥。
自定义扩展词库
进入到config/analysis-ik/(插件命令安装方式) 或plugins/analysis-ik/config(安装包安装方式) 目录下,新增自定义词典:
vim rubin_ext_dict.dic
输入:
江大桥将我们自定义的扩展词典文件添加到IKAnalyzer.cfg.xml配置中:
vim IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">rubin_ext_dict.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">rubin_stop_dict.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
重启Elasticsearch。
停用词典使用
停用词:有些词在文本中出现的频率非常高。但对本文的语义产生不了多大的影响。例如英文的a、an、the、of等。或中文的”的、了、呢等”。这样的词称为停用词。停用词经常被过滤掉,不会被进行索引。在检索的过程中,如果用户的查询词中含有停用词,系统会自动过滤掉。停用词可以加快索引的速度,减少索引库文件的大小。
自定义停用词库
进入到config/analysis-ik/(插件命令安装方式) 或plugins/analysis-ik/config(安装包安装方式) 目录下,新增自定义词典:
vim rubin_stop_dict.dic
输入:
的
了
啊将我们自定义的停用词典文件添加到IKAnalyzer.cfg.xml配置中:
vim IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">rubin_ext_dict.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">rubin_stop_dict.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>重启Elasticsearch。
同义词典使用
语言博大精深,有很多相同意思的词,我们称之为同义词,比如“番茄”和“西红柿”,“馒头”和“馍”等。在搜索的时候,我们输入的可能是“番茄”,但是应该把含有“西红柿”的数据一起查询出来,这种情况叫做同义词查询。
注意:扩展词和停用词是在索引的时候使用,而同义词是检索时候使用。
配置IK同义词
Elasticsearch自带一个名为synonym的同义词filter。为了能让IK和synonym同时工作,我们需要定义新的analyzer,用IK做tokenizer,synonym做filter。听上去很复杂,实际上要做的只是加一段配置。
创建config/analysis-ik/synonym.txt文件, 创建synonym.txt文件,输入一些同义词并存为utf-8格式。例如:
vim synonym.txt
添加:
rubin,虾米
china,中国创建索引时,使用同义词配置,示例模板如下:
PUT /synonym_index
{
"settings": {
"analysis": {
"filter": {
"word_sync": {
"type": "synonym",
"synonyms_path": "analysis-ik/synonym.txt"
}
},
"analyzer": {
"ik_sync_max_word": {
"filter": [
"word_sync"
],
"type": "custom",
"tokenizer": "ik_max_word"
},
"ik_sync_smart": {
"filter": [
"word_sync"
],
"type": "custom",
"tokenizer": "ik_smart"
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_sync_max_word",
"search_analyzer": "ik_sync_max_word"
}
}
}
}插入数据:
POST /synonym_index/_doc/1
{
"name": "虾米是中国最盛产的海鲜资源"
}使用同义词"rubin"或者“china”进行搜索:
POST /synonym_index/_search
{
"query": {
"match": {
"name": "rubin"
}
}
}索引操作(创建、查看、删除)
创建索引库
Elasticsearch采用Rest风格API,因此其API就是一次http请求,你可以用任何工具发起http请求。语法如下:
PUT /索引名称
{
"settings": {
"属性名": "属性值"
}
}settings:就是索引库设置,其中可以定义索引库的各种属性 比如分片数 副本数等,目前我们可以不设置,都走默认。
示例:
PUT /rubin_index判断索引是否存在
语法:
HEAD /索引名称示例:
HEAD /rubin_index查看索引
Get请求可以帮我们查看索引的相关属性信息,格式:
查看单个索引
语法:
GET /索引名称示例:
GET /rubin_index批量查看索引
语法:
GET /索引名称1,索引名称2,索引名称3,...示例:
GET /rubin_index,rubin_user_index查看所有索引
语法:
GET _all或者
GET /_cat/indices?v其中的颜色说明如下:
- 绿色:索引的所有分片都正常分配
- 黄色:至少有一个副本没有得到正确的分配
- 红色:至少有一个主分片没有得到正确的分配
打开索引
语法:
POST /索引名称/_open关闭索引
语法:
POST /索引名称/_close删除索引库
语法:
DELETE /索引名称1,索引名称2,索引名称3...映射操作
索引创建之后,等于有了关系型数据库中的database。Elasticsearch7.x取消了索引type类型的设置,不允许指定类型,默认为_doc,但字段仍然是有的,我们需要设置字段的约束信息,叫做字段映射(mapping)。
字段的约束包括但不限于:
- 字段的数据类型
- 是否要存储
- 是否要索引
- 分词器
创建映射字段
语法:
PUT /索引库名/_mapping
{
"properties": {
"字段名": {
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
}
}
}文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.3/mapping-params.html。
字段名:任意填写,下面指定许多属性,例如:
- type:类型,可以是text、long、short、date、integer、object等
- index:是否索引,默认为true
- store:是否存储,默认为false
- analyzer:指定分词器
示例:
PUT /rubin_user_index
PUT /rubin_user_index/_mapping/
{
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word"
},
"motto": {
"type": "text",
"analyzer": "ik_max_word"
},
"nickname": {
"type": "keyword",
"index": "false"
},
"age": {
"type": "integer"
}
}
}映射属性详解
type
Elasticsearch中支持的数据类型非常丰富,文档地址为:https://www.elastic.co/guide/en/elasticsearch/reference/7.3/mapping-types.html。
我们说几个关键的:
- String类型,又分两种:text:可分词,不可参与聚合;keyword:不可分词,数据会作为完整字段进行匹配,可以参与聚合
- Numerical:数值类型,分两类:基本数据类型:long、interger、short、byte、double、float、half_float;浮点数的高精度类型:scaled_float,需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时再原
- Date:日期类型。elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间
- Array:数组类型。进行匹配时,任意一个元素满足,都认为满足。排序时,如果升序则用数组中的最小值来排序,如果降序则用数组中的最大值来排序
- Object:对象。
{
name:"Jack",
age:21,
girl:{
name: "Rose",
age:21
}
}如果存储到索引库的是对象类型,例如上面的girl,会把girl变成两个字段:girl.name和girl.age。
index
index影响字段的索引情况如下:
- true:字段会被索引,则可以用来进行搜索。默认值就是true
- false:字段不会被索引,不能用来搜索
index的默认值就是true,也就是说你不进行任何配置,所有字段都会被索引。
但是有些字段是我们不希望被索引的,比如企业的logo图片地址,就需要手动设置index为false。
store
是否将数据进行独立存储。
原始的文本会存储在_source里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source里面提取出来的。当然你也可以独立的存储某个字段,只要设置store:true即可,获取独立存储的字段要比从_source中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置,默认为false。
analyzer
指定分词器。
一般我们处理中文会选择ik分词器ik_max_word、ik_smart。
查看映射关系
查看单个索引映射关系
语法:
GET /索引名称/_mapping查看所有索引映射关系
语法:
GET _mapping或者
GET _all/_mapping修改索引映射关系
语法:
PUT /索引库名/_mapping
{
"properties": {
"字段名": {
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
}
}
} 注意:修改映射增加字段。做其它更改只能删除索引,重新建立映射。
一次性创建索引和映射
刚才 的案例中我们是把创建索引库和映射分开来做,其实也可以在创建索引库的同时,直接制定索引库中的索引,基本语法:
put /索引库名称
{
"settings":{
"索引库属性名":"索引库属性值"
},
"mappings":{
"properties":{
"字段名":{
"映射属性名":"映射属性值"
}
}
}
}示例:
PUT /rubin_user_index
{
"settings": {},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word"
},
"motto": {
"type": "text",
"analyzer": "ik_max_word"
},
"nickname": {
"type": "keyword",
"index": "false"
},
"age": {
"type": "integer"
}
}
}
}文档增删改查及局部更新
文档,即索引库中的数据,会根据规则创建索引,将来用于搜索。可以类比做数据库中的一行数据。
新增文档
新增文档时,涉及到id的创建方式,手动指定或者自动生成。
新增文档(手动指定id)
语法:
POST /索引名称/_doc/{id}
{
"field":"value"
}示例:
POST /rubin_user_index/_doc/1
{
"name": "rubin",
"motto": "人生不止眼前的苟且",
"nickname": "虾米",
"age": 27
}新增文档(自动生成id)
语法:
POST /索引名称/_doc
{
"field":"value"
}示例:
POST /rubin_user_index/_doc
{
"name": "rubin",
"motto": "人生不止眼前的苟且",
"nickname": "虾米",
"age": 27
}响应示例:
{
"_index" : "rubin_user_index",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}可以看到结果显示为: created ,代表创建成功。
另外,需要注意的是,在响应结果中有个_id字段,这个就是这条文档数据的唯一标识 ,以后的增删改查都依赖这个_id作为唯一标示,这里是Elasticsearch帮我们随机生成的id。
查看单个文档
语法:
GET /索引名称/_doc/{id}示例:
GET /rubin_user_index/_doc/1响应示例:
{
"_index" : "rubin_user_index",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "rubin",
"motto" : "人生不止眼前的苟且",
"nickname" : "虾米",
"age" : 27
}
}
文档元数据解读:
| 元数据项 | 含义 |
| _index | document所属index |
| _type | document所属type,Elasticsearch7.x默认type为_doc |
| _id | 代表document的唯一标识,与index和type一起,可以唯一标识和定位一个document |
| _version | document的版本号,Elasticsearch利用_version (版本号)的方式来确保应用中相互冲突的变更不会导致数据丢失。需要修改数据时,需要指定想要修改文档的version号,如果该版本不是当前版本号,请求将会失败 |
| _seq_no | 严格递增的顺序号,每个文档一个,Shard级别严格递增,保证后写入的Doc的seq_no大于先写入的Doc的seq_no |
| _primary_term | 任何类型的写操作,包括index、create、update和delete,都会生成一个_seq_no |
| found | true/false,是否查找到文档 |
| _source | 存储原始文档 |
查看所有文档
语法:
POST /索引名称/_search
{
"query":{
"match_all": {
}
}
}_source定制返回结果
某些业务场景下,我们不需要搜索引擎返回source中的所有字段,可以使用source进行定制,如下,多个字段之间使用逗号分隔。
语法:
GET /索引名称/_doc/{id}?_source=field1,field2更新文档(全部更新)
把刚才新增的请求方式改为PUT,就是修改了,不过修改必须指定id。id对应文档存在,则修改,id对应文档不存在,则新增。
语法:
PUT /索引名称/_doc
{
"field":"value"
}更新文档(局部更新)
Elasticsearch可以使用PUT或者POST对文档进行更新(全部更新),如果指定id的文档已经存在,则执行更新操作。
注意:Elasticsearch执行更新操作的时候,Elasticsearch首先将旧的文档标记为删除状态,然后添加新的文档,旧的文档不会立即消失,但是你也无法访问,Elasticsearch会在你继续添加更多数据的时候在后台清理已经标记为删除状态的文档。
全部更新,是直接把之前的老数据,标记为删除状态,然后,再添加一条更新的(使用PUT或者POST)。局域更新,只是修改某个字段(使用POST)。
语法:
POST /索引名/_update/{id}
{
"doc":{
"field":"value"
}
}删除文档
根据id进行删除
语法:
DELETE /索引名/_doc/{id}根据查询条件进行删除
语法:
POST /索引库名/_delete_by_query
{
"query": {
"match": {
"字段名": "搜索关键字"
}
}
}删除所有文档
POST /索引名/_delete_by_query
{
"query": {
"match_all": {}
}
}文档的全量替换、强制创建
全量替换
- 语法与创建文档是一样的,如果文档
id不存在,那么就是创建;如果文档id已经存在,那么就是全量替换操作,替换文档的json串内容 - 文档是不可变的,如果要修改文档的内容,第一种方式就是全量替换,直接对文档重新建立索引,替换里面所有的内容,elasticsearch会将老的文档标记为
deleted,然后新增我们给定的一个文档,当我们创建越来越多的文档的时候,elasticsearch会在适当的时机在后台自动删除标记为deleted的文档
强制创建
PUT /index/_doc/{id}?op_type=create {},PUT /index/_doc/{id}/_create {}注意:如果id存在就会报错。
以上就是本文的全部内容。欢迎各位小伙伴积极留言交流~~~

文章评论