核心概念
表概念
- 真实表:数据库中真实存在的物理表。例如b_order0、b_order1
- 逻辑表:在分片之后,同一类表结构的名称(总成)。例如b_order
- 数据节点:在分片之后,由数据源和数据表组成。例如ds0.b_order1
- 绑定表:指的是分片规则一致的关系表(主表、子表),例如b_order和b_order_item,均按照order_id分片,则此两个表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,可以提升关联查询效率
- 广播表:在使用中,有些表没必要做分片,例如字典表、省份信息等,因为他们数据量不大,而且这种表可能需要与海量数据的表进行关联查询。广播表会在不同的数据节点上进行存储,存储的表结构和数据完全相同
分片算法(ShardingAlgorithm)
由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。目前提供4种分片算法:
- 精确分片算法
PreciseShardingAlgorithm:用于处理使用单一键作为分片键的=与IN进行分片的场景 - 范围分片算法
RangeShardingAlgorithm:用于处理使用单一键作为分片键的BETWEEN AND、>、<、>=、<=进行分片的场景 - 复合分片算法
ComplexKeysShardingAlgorithm:用于处理使用多键作为分片键进行分片的场景,多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度 - Hint分片算法
HintShardingAlgorithm:用于处理使用Hint行分片的场景。对于分片字段非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。例:内部系统,按照员工登录主键分库,而数据库中并无此字段。SQL Hint支持通过Java API和SQL注释两种方式使用
分片策略(ShardingStrategy)
分片策略包含分片键和分片算法,真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供5种分片策略:
- 标准分片策略
StandardShardingStrategy:只支持单分片键,提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。PreciseShardingAlgorithm是必选的,RangeShardingAlgorithm是可选的。但是SQL中使用了范围操作,如果不配置RangeShardingAlgorithm会采用全库路由扫描,效率低 - 复合分片策略
ComplexShardingStrategy:支持多分片键。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度 - 行表达式分片策略
InlineShardingStrategy:只支持单分片键。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发。如:t_user_$->{u_id % 8}表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7 - Hint分片策略
HintShardingStrategy:通过Hint指定分片值而非从SQL中提取分片值的方式进行分片的策略 - 不分片策略
NoneShardingStrategy:不分片的策略
分片策略配置
对于分片策略存有数据源分片策略和表分片策略两种维度,两种策略的API完全相同。
- 数据源分片策略:用于配置数据被分配的目标数据源
- 表分片策略:用于配置数据被分配的目标表,由于表存在与数据源内,所以表分片策略是依赖数据源分片策略结果的
流程剖析
ShardingSphere 3个产品的数据分片功能主要流程是完全一致的,如下图所示。

SQL解析
SQL解析分为词法解析和语法解析。 先通过词法解析器将SQL拆分为一个个不可再分的单词。再使用语法解析器对SQL进行理解,并最终提炼出解析上下文。
Sharding-JDBC采用不同的解析器对SQL进行解析,解析器类型如下:
- MySQL解析器
- Oracle解析器
- SQLServer解析器
- PostgreSQL解析器
- 默认SQL解析器
查询优化
负责合并和优化分片条件,如OR等。
SQL路由
根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。
SQL改写
将SQL改写为在真实数据库中可以正确执行的语句。SQL改写分为正确性改写和优化改写。
SQL执行
通过多线程执行器异步执行SQL。
结果归并
将多个执行结果集归并以便于通过统一的JDBC接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
SQL使用规范
支持项
- 路由至单数据节点时,目前MySQL数据库100%全兼容,其他数据库完善中
- 路由至多数据节点时,全面支持DQL、DML、DDL、DCL、TCL。支持分页、去重、排序、分组、聚合、关联查询(不支持跨库关联)。以下用最为复杂的查询为例:
SELECT select_expr [, select_expr ...]
FROM table_reference [, table_reference ...]
[WHERE predicates]
[GROUP BY {col_name | position} [ASC | DESC], ...]
[ORDER BY {col_name | position} [ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]- 支持分页子查询,但其他子查询有限支持,无论嵌套多少层,只能解析至第一个包含数据表的子查询,一旦在下层嵌套中再次找到包含数据表的子查询将直接抛出解析异常。例如,以下子查询可以支持:
SELECT COUNT(*) FROM (SELECT * FROM b_order o)以下子查询不支持:
SELECT COUNT(*) FROM (SELECT * FROM b_order o WHERE o.id IN (SELECT id
FROM b_order WHERE status = ?))简单来说,通过子查询进行非功能需求,在大部分情况下是可以支持的。比如分页、统计总数等;而通过子查询实现业务查询当前并不能支持。
- 当分片键处于运算表达式或函数中的SQL时,将采用全路由的形式获取结果
例如下面SQL,create_time为分片键:
SELECT * FROM b_order WHERE to_date(create_time, 'yyyy-mm-dd') = '2020-
05-05';由于ShardingSphere只能通过SQL字面提取用于分片的值,因此当分片键处于运算表达式或函数中时,ShardingSphere无法提前获取分片键位于数据库中的值,从而无法计算出真正的分片值。
- 完全支持MySQL和Oracle的分页查询,SQLServer由于分页查询较为复杂,仅部分支持。
性能瓶颈:
查询偏移量过大的分页会导致数据库获取数据性能低下,以MySQL为例:
SELECT * FROM b_order ORDER BY id LIMIT 1000000, 10这句SQL会使得MySQL在无法利用索引的情况下跳过1000000条记录后,再获取10条记录,其性能可想而知。 而在分库分表的情况下(假设分为2个库),为了保证数据的正确性,SQL会改写为:
SELECT * FROM b_order ORDER BY id LIMIT 0, 1000010即将偏移量前的记录全部取出,并仅获取排序后的最后10条记录。这会在数据库本身就执行很慢的情况下,进一步加剧性能瓶颈。 因为原SQL仅需要传输10条记录至客户端,而改写之后的SQL则会传输1,000,010 * 2的记录至客户端。
ShardingSphere的优化:
ShardingSphere进行了以下2个方面的优化:首先,采用流式处理 + 归并排序的方式来避免内存的过量占用。其次,ShardingSphere对仅落至单节点的查询进行进一步优化。
分页方案优化:
由于LIMIT并不能通过索引查询数据,因此如果可以保证ID的连续性,通过ID进行分页是比较好的解决方案:
SELECT * FROM b_order WHERE id > 1000000 AND id <= 1000010 ORDER BY id或通过记录上次查询结果的最后一条记录的ID进行下一页的查询:
SELECT * FROM b_order WHERE id > 1000000 LIMIT 10不支持项(路由至多数据节点)
- 不支持
CASE WHEN、HAVING、UNION (ALL) - 由于归并的限制,子查询中包含聚合函数目前无法支持
- 不支持包含schema的SQL。因为ShardingSphere的理念是像使用一个数据源一样使用多数据源,因此对SQL的访问都是在同一个逻辑schema之上
不支持的SQL示例:
INSERT INTO tbl_name (col1, col2, …) VALUES(1+2, ?, …) //VALUES语句不支持运算
表达式
INSERT INTO tbl_name (col1, col2, …) SELECT col1, col2, … FROM tbl_name
WHERE col3 = ? //INSERT .. SELECT
SELECT COUNT(col1) as count_alias FROM tbl_name GROUP BY col1 HAVING
count_alias > ? //HAVING
SELECT * FROM tbl_name1 UNION SELECT * FROM tbl_name2 //UNION
SELECT * FROM tbl_name1 UNION ALL SELECT * FROM tbl_name2 //UNION ALL
SELECT * FROM ds.tbl_name1 //包含schema
SELECT SUM(DISTINCT col1), SUM(col1) FROM tbl_name //同时使用普通聚合函数
和DISTINCT
SELECT * FROM tbl_name WHERE to_date(create_time, ‘yyyy-mm-dd’) = ? //会导致
全路由其他功能
Inline行表达式
InlineShardingStrategy:采用Inline行表达式进行分片的配置。
Inline是可以简化数据节点和分片算法配置信息。主要是解决配置简化、配置一体化。
语法格式:
行表达式的使用非常直观,只需要在配置中使用${ expression }或$->{ expression }标识行表达式即可。例如:
${begin..end} 表示范围区间
${[unit1, unit2, unit_x]} 表示枚举值行表达式中如果出现多个${}或$->{}表达式,整个表达式结果会将每个子表达式结果进行笛卡尔(积)组合。例如,以下行表达式:
${['online', 'offline']}_table${1..3}
$->{['online', 'offline']}_table$->{1..3}最终会解析为:
online_table1, online_table2, online_table3,
offline_table1, offline_table2, offline_table3数据节点配置:
对于均匀分布的数据节点,如果数据结构如下:
db0
├── b_order2
└── b_order1
db1
├── b_order2
└── b_order1用行表达式可以简化为:
db${0..1}.b_order${1..2}
或者
db$->{0..1}.b_order$->{1..2}对于自定义的数据节点,如果数据结构如下:
b0
├── b_order0
└── b_order1
db1
├── b_order2
├── b_order3
└── b_order4用行表达式可以简化为:
db0.b_order${0..1},db1.b_order${2..4}分片算法配置:
行表达式内部的表达式本质上是一段Groovy代码,可以根据分片键进行计算的方式,返回相应的真实数据源或真实表名称。
ds${id % 10}
或者
ds$->{id % 10}结果为:ds0、ds1、ds2… ds9
分布式主键
ShardingSphere不仅提供了内置的分布式主键生成器,例如UUID、SNOWFLAKE,还抽离出分布式主键生成器的接口,方便用户自行实现自定义的自增主键生成器。
内置主键生成器:
UUID:采用UUID.randomUUID()的方式产生分布式主键SNOWFLAKE:在分片规则配置模块可配置每个表的主键生成策略,默认使用雪花算法,生成64bit的长整型数据
自定义主键生成器:
- 自定义主键类,实现
ShardingKeyGenerator接口 - 按SPI规范配置自定义主键类。在Apache ShardingSphere中,很多功能实现类的加载方式是通过
SPI注入的方式完成的(注意:在resources目录下新建META-INF文件夹,再新建services文件夹,然后新建文件的名字为org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator,打开文件,复制自定义主键类全路径到文件中保存) - 自定义主键类应用配置
#对应主键字段名
spring.shardingsphere.sharding.tables.t_book.key-generator.column=id
#对应主键类getType返回内容
spring.shardingsphere.sharding.tables.t_book.key-
generator.type=RUBIN-KEY分库分表实战
由于ShardingJDBC的相关jar包还没有上传到Maven的仓库,所以需要我们自己手动编译安装。在github或者附件中下载对应的源码包,进入源码包执行如下命令安装:
mvn clean install -Dmaven.test.skip=true源码包中只有支持XA事务的事务管理器,我们使用BASE模式的saga需要自行导入saga的jar。可以下载附件中的仓库压缩包,解压之后放入本地的Maven仓库即可。
新建一个SpringBoot项目sharding-jdbc-demo,其pom结构如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.9.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.rubin</groupId>
<artifactId>sharding-jdbc-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>sharding-jdbc-demo</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.compile.sourceEncoding>UTF-8</project.compile.sourceEncoding>
<sharding-jdbc.version>4.1.0</sharding-jdbc.version>
<mysql-connector.version>5.1.48</mysql-connector.version>
</properties>
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql-connector.version}</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-jdbc.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
启动类:
package com.rubin.shardingjdbcdemo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.domain.EntityScan;
@SpringBootApplication
@EntityScan(basePackages = "com.rubin.shardingjdbcdemo.entity")
public class ShardingJdbcDemoApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingJdbcDemoApplication.class, args);
}
}
我们新建两个数据库:rubin_shard_1和rubin_shard_2,导入如下SQL:
CREATE TABLE `position`
(
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`name` varchar(256) DEFAULT NULL,
`salary` varchar(50) DEFAULT NULL,
`city` varchar(256) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE `position_detail`
(
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`pid` bigint(11) NOT NULL DEFAULT '0',
`description` text DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE `city`
(
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`name` varchar(256) DEFAULT NULL,
`province` varchar(256) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE `b_order0`
(
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`is_del` bit(1) NOT NULL DEFAULT 0 COMMENT '是否被删除',
`company_id` int(11) NOT NULL COMMENT '公司ID',
`position_id` bigint(11) NOT NULL COMMENT '职位ID',
`user_id` int(11) NOT NULL COMMENT '用户id',
`publish_user_id` int(11) NOT NULL COMMENT '职位发布者id',
`resume_type` int(2) NOT NULL DEFAULT 0 COMMENT '简历类型:0 附件 1 在线',
`status` varchar(256) NOT NULL COMMENT '投递状态 投递状态 WAIT-待处理 AUTO_FILTER-自动过滤 PREPARE_CONTACT-待沟通 REFUSE-拒绝 ARRANGE_INTERVIEW-通知面试',
`create_time` datetime NOT NULL COMMENT '创建时间',
`operate_time` datetime NOT NULL COMMENT '操作时间',
`work_year` varchar(100) DEFAULT NULL COMMENT '工作年限',
`name` varchar(256) DEFAULT NULL COMMENT '投递简历人名字',
`position_name` varchar(256) DEFAULT NULL COMMENT '职位名称',
`resume_id` int(10) DEFAULT NULL COMMENT '投递的简历id(在线和附件都记录,通过resumeType进行区别在线还是附件)',
PRIMARY KEY (`id`),
KEY `index_createTime` (`create_time`),
KEY `index_companyId_status` (`company_id`, `status`(255), `is_del`),
KEY `i_comId_pub_ctime` (`company_id`, `publish_user_id`, `create_time`),
KEY `index_companyId_positionId` (`company_id`, `position_id`) USING BTREE
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE `b_order1`
(
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`is_del` bit(1) NOT NULL DEFAULT 0 COMMENT '是否被删除',
`company_id` int(11) NOT NULL COMMENT '公司ID',
`position_id` bigint(11) NOT NULL COMMENT '职位ID',
`user_id` int(11) NOT NULL COMMENT '用户id',
`publish_user_id` int(11) NOT NULL COMMENT '职位发布者id',
`resume_type` int(2) NOT NULL DEFAULT 0 COMMENT '简历类型:0 附件 1 在线',
`status` varchar(256) NOT NULL COMMENT '投递状态 投递状态 WAIT-待处理 AUTO_FILTER-自动过滤 PREPARE_CONTACT-待沟通 REFUSE-拒绝 ARRANGE_INTERVIEW-通知面试',
`create_time` datetime NOT NULL COMMENT '创建时间',
`operate_time` datetime NOT NULL COMMENT '操作时间',
`work_year` varchar(100) DEFAULT NULL COMMENT '工作年限',
`name` varchar(256) DEFAULT NULL COMMENT '投递简历人名字',
`position_name` varchar(256) DEFAULT NULL COMMENT '职位名称',
`resume_id` int(10) DEFAULT NULL COMMENT '投递的简历id(在线和附件都记录,通过resumeType进行区别在线还是附件)',
PRIMARY KEY (`id`),
KEY `index_createTime` (`create_time`),
KEY `index_companyId_status` (`company_id`, `status`(255), `is_del`),
KEY `i_comId_pub_ctime` (`company_id`, `publish_user_id`, `create_time`),
KEY `index_companyId_positionId` (`company_id`, `position_id`) USING BTREE
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE `c_order`
(
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`is_del` bit(1) NOT NULL DEFAULT 0 COMMENT '是否被删除',
`user_id` int(11) NOT NULL COMMENT '用户id',
`company_id` int(11) NOT NULL COMMENT '公司id',
`publish_user_id` int(11) NOT NULL COMMENT 'B端用户id',
`position_id` int(11) NOT NULL COMMENT '职位ID',
`resume_type` int(2) NOT NULL DEFAULT 0 COMMENT '简历类型:0 附件 1 在线',
`status` varchar(256) NOT NULL COMMENT '投递状态 投递状态 WAIT-待处理 AUTO_FILTER-自动过滤 PREPARE_CONTACT-待沟通 REFUSE-拒绝 ARRANGE_INTERVIEW-通知面试',
`create_time` datetime NOT NULL COMMENT '创建时间',
`update_time` datetime NOT NULL COMMENT '处理时间',
PRIMARY KEY (`id`),
KEY `index_userId_positionId` (`user_id`, `position_id`),
KEY `idx_userId_operateTime` (`user_id`, `update_time`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE `c_user`
(
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`name` varchar(256) DEFAULT NULL,
`pwd_plain` varchar(256) DEFAULT NULL,
`pwd_cipher` varchar(256) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;定义JPA的Entity和Repository:
package com.rubin.shardingjdbcdemo.entity;
import lombok.Data;
import javax.persistence.*;
import java.io.Serializable;
import java.util.Date;
@Data
@Entity
@Table(name = "b_order")
public class BOrder implements Serializable {
@Id
@Column(name = "id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
@Column(name = "is_del")
private Boolean isDel;
@Column(name = "company_id")
private Integer companyId;
@Column(name = "position_id")
private long positionId;
@Column(name = "user_id")
private Integer userId;
@Column(name = "publish_user_id")
private Integer publishUserId;
@Column(name = "resume_type")
private Integer resumeType;
@Column(name = "status")
private String status;
@Column(name = "create_time")
private Date createTime;
@Column(name = "operate_time")
private Date operateTime;
@Column(name = "work_year")
private String workYear;
@Column(name = "name")
private String name;
@Column(name = "position_name")
private String positionName;
@Column(name = "resume_id")
private Integer resumeId;
}
package com.rubin.shardingjdbcdemo.repository;
import com.rubin.shardingjdbcdemo.entity.BOrder;
import org.springframework.data.jpa.repository.JpaRepository;
public interface BOrderRepository extends JpaRepository<BOrder,Long> {
}
package com.rubin.shardingjdbcdemo.entity;
import lombok.Data;
import javax.persistence.*;
import java.io.Serializable;
@Data
@Entity
@Table(name = "city")
public class City implements Serializable {
@Id
@Column(name = "id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
@Column(name = "name")
private String name;
@Column(name = "province")
private String province;
}
package com.rubin.shardingjdbcdemo.repository;
import com.rubin.shardingjdbcdemo.entity.City;
import org.springframework.data.jpa.repository.JpaRepository;
public interface CityRepository extends JpaRepository<City, Long> {
}
package com.rubin.shardingjdbcdemo.entity;
import lombok.Data;
import javax.persistence.*;
import java.io.Serializable;
@Data
@Entity
@Table(name = "c_user")
public class CUser implements Serializable {
@Id
@Column(name = "id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
@Column(name = "name")
private String name;
@Column(name = "pwd")//逻辑列名
private String pwd;
}
package com.rubin.shardingjdbcdemo.repository;
import com.rubin.shardingjdbcdemo.entity.CUser;
import org.springframework.data.jpa.repository.JpaRepository;
import java.util.List;
public interface CUserRepository extends JpaRepository<CUser, Long> {
List<CUser> findByPwd(String pwd);
}
package com.rubin.shardingjdbcdemo.entity;
import lombok.Data;
import javax.persistence.*;
import java.io.Serializable;
@Data
@Entity
@Table(name = "position_detail")
public class PositionDetail implements Serializable {
@Id
@Column(name = "id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
@Column(name = "pid")
private long pid;
@Column(name = "description")
private String description;
}
package com.rubin.shardingjdbcdemo.repository;
import com.rubin.shardingjdbcdemo.entity.PositionDetail;
import org.springframework.data.jpa.repository.JpaRepository;
public interface PositionDetailRepository extends JpaRepository<PositionDetail, Long> {
}
package com.rubin.shardingjdbcdemo.entity;
import lombok.Data;
import javax.persistence.*;
import java.io.Serializable;
@Data
@Entity
@Table(name = "position")
public class Position implements Serializable {
@Id
@Column(name = "id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
@Column(name = "name")
private String name;
@Column(name = "salary")
private String salary;
@Column(name = "city")
private String city;
}
package com.rubin.shardingjdbcdemo.repository;
import com.rubin.shardingjdbcdemo.entity.Position;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
public interface PositionRepository extends JpaRepository<Position, Long> {
@Query(nativeQuery = true, value = "select p.id,p.name,p.salary,p.city,pd.description from position p join position_detail pd on(p.id=pd.pid) where p.id=:id")
Object findPositionsById(@Param("id") long id);
}
编写我们的自定义主键生成器:
package com.rubin.shardingjdbcdemo.id;
import org.apache.shardingsphere.core.strategy.keygen.SnowflakeShardingKeyGenerator;
import org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator;
import java.util.Properties;
public class RubinId implements ShardingKeyGenerator {
private SnowflakeShardingKeyGenerator snow = new SnowflakeShardingKeyGenerator();
@Override
public Comparable<?> generateKey() {
System.out.println("------执行了自定义主键生成器RubinId-------");
return snow.generateKey();
}
@Override
public String getType() {
return "RUBIN-KEY";
}
@Override
public Properties getProperties() {
return null;
}
@Override
public void setProperties(Properties properties) {
}
}
配置主键生成器:
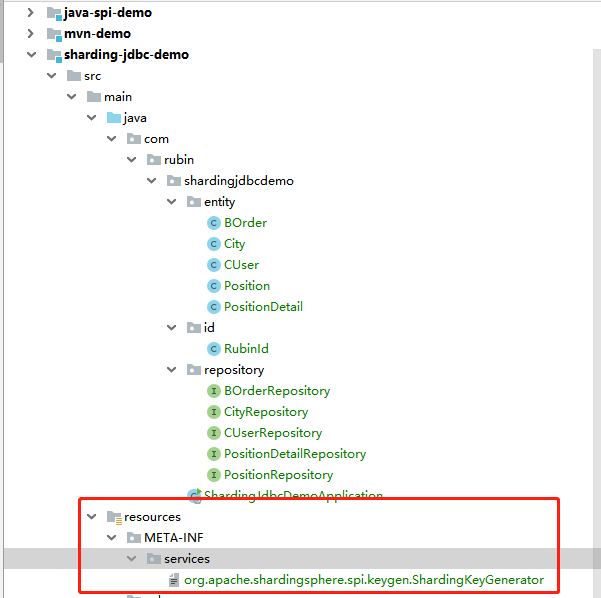
文件内容为:
com.rubin.shardingjdbcdemo.id.RubinId编写配置文件如下:
application.properties
spring.profiles.active=sharding-database
spring.shardingsphere.props.sql.show=trueapplication-sharding-database.properties
# datasource
spring.shardingsphere.datasource.names=ds0,ds1
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://127.0.0.1:3306/rubin_shard_1?characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=123456
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://127.0.0.1:3306/rubin_shard_2?characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=123456
# sharding-database
spring.shardingsphere.sharding.tables.position.database-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.position.database-strategy.inline.algorithm-expression=ds$->{id % 2}
spring.shardingsphere.sharding.tables.position_detail.database-strategy.inline.sharding-column=pid
spring.shardingsphere.sharding.tables.position_detail.database-strategy.inline.algorithm-expression=ds$->{pid % 2}
# id
spring.shardingsphere.sharding.tables.position.key-generator.column=id
spring.shardingsphere.sharding.tables.position.key-generator.type=RUBIN-KEY
spring.shardingsphere.sharding.tables.position_detail.key-generator.column=id
spring.shardingsphere.sharding.tables.position_detail.key-generator.type=SNOWFLAKE
# broadcast
spring.shardingsphere.sharding.broadcast-tables=city
spring.shardingsphere.sharding.tables.city.key-generator.column=id
spring.shardingsphere.sharding.tables.city.key-generator.type=SNOWFLAKE
# sharding-database-table
spring.shardingsphere.sharding.tables.b_order.database-strategy.inline.sharding-column=company_id
spring.shardingsphere.sharding.tables.b_order.database-strategy.inline.algorithm-expression=ds$->{company_id % 2}
spring.shardingsphere.sharding.tables.b_order.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.b_order.table-strategy.inline.algorithm-expression=b_order${id % 2}
spring.shardingsphere.sharding.tables.b_order.actual-data-nodes=ds${0..1}.b_order${0..1}
spring.shardingsphere.sharding.tables.b_order.key-generator.column=id
spring.shardingsphere.sharding.tables.b_order.key-generator.type=SNOWFLAKE
编写测试类:
package com.rubin.shardingjdbcdemo;
import com.rubin.shardingjdbcdemo.entity.BOrder;
import com.rubin.shardingjdbcdemo.entity.City;
import com.rubin.shardingjdbcdemo.entity.Position;
import com.rubin.shardingjdbcdemo.entity.PositionDetail;
import com.rubin.shardingjdbcdemo.repository.BOrderRepository;
import com.rubin.shardingjdbcdemo.repository.CityRepository;
import com.rubin.shardingjdbcdemo.repository.PositionDetailRepository;
import com.rubin.shardingjdbcdemo.repository.PositionRepository;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.annotation.Repeat;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.Date;
import java.util.Random;
@SpringBootTest(classes = ShardingJdbcDemoApplication.class)
@RunWith(SpringRunner.class)
public class TestShardingDatabase {
@Autowired
private PositionRepository positionRepository;
@Autowired
private PositionDetailRepository positionDetailRepository;
@Autowired
private CityRepository cityRepository;
@Autowired
private BOrderRepository orderRepository;
/**
* 测试分库插入数据
*/
@Test
public void testAdd() {
for (int i = 1; i <= 20; i++) {
Position position = new Position();
position.setName("lagou" + i);
position.setSalary("1000000");
position.setCity("beijing");
positionRepository.save(position);
}
}
/**
* 测试分库插入关联数据
*/
@Test
public void testAdd2() {
for (int i = 1; i <= 20; i++) {
Position position = new Position();
position.setName("lagou" + i);
position.setSalary("1000000");
position.setCity("beijing");
positionRepository.save(position);
PositionDetail positionDetail = new PositionDetail();
positionDetail.setPid(position.getId());
positionDetail.setDescription("this is a message " + i);
positionDetailRepository.save(positionDetail);
}
}
/**
* 测试分库关联查询
*/
@Test
public void testLoad() {
Object object = positionRepository.findPositionsById(660510791585234944L);
Object[] position = (Object[]) object;
System.out.println(position[0] + " " + position[1] + " " + position[2] + " " + position[3] + " " + position[4]);
}
/**
* 测试广播表插入
*/
@Test
public void testBroadCast() {
City city = new City();
city.setName("beijing");
city.setProvince("beijing");
cityRepository.save(city);
}
/**
* 分库又分表插入测试
*/
@Test
@Repeat(100)
public void testShardingBOrder() {
Random random = new Random();
int companyId = random.nextInt(10);
BOrder order = new BOrder();
order.setIsDel(false);
order.setCompanyId(companyId);
order.setPositionId(3242342);
order.setUserId(2222);
order.setPublishUserId(1111);
order.setResumeType(1);
order.setStatus("AUTO");
order.setCreateTime(new Date());
order.setOperateTime(new Date());
order.setWorkYear("2");
order.setName("lagou");
order.setPositionName("Java");
order.setResumeId(23233);
orderRepository.save(order);
}
}
以上的测试类涵盖了我们上述所有内容,案例比较简单,这里就不一一赘述了。本博文的内容就到此结束了,欢迎小伙伴们积极留言交流~~~
附件
链接:https://pan.rubinchu.com/share/1458632259782311936
提取码:xn8x

文章评论