集群应用场景
消息传递
Kafka可以很好地替代传统邮件代理。消息代理的使用有多种原因(将处理与数据生产者分离,缓冲未处理的消息等)。与大多数邮件系统相比,Kafka具有更好的吞吐量,内置的分区,复制和容错功能,这使其成为大规模邮件处理应用程序的理想解决方案。
在这个领域,Kafka与ActiveMQ或 RabbitMQ等传统消息传递系统相当。
网站活动路由
Kafka最初的用例是能够将用户活动跟踪管道重建为一组实时的发布-订阅。这意味着将网站活动(页面浏览,搜索或用户可能采取的其他操作)发布到中心主题,每种活动类型只有一个主题。这些提要可用于一系列用例的订阅,包括实时处理,实时监控,以及加载到Hadoop或脱机数据仓库系统中以进行脱机处理和报告。
活动跟踪通常量很大,因为每个用户页面视图都会生成许多活动消息。
监控指标
Kafka通常用于操作监控数据。这涉及汇总来自分布式应用程序的统计信息,以生成操作数据的集中。
日志汇总
许多人使用Kafka代替日志聚合解决方案。日志聚合通常从服务器收集物理日志文件,并将它们放在中央位置(也许是文件服务器或HDFS)以进行处理。Kafka提取文件的详细信息,并以日志流的形式更清晰地抽象日志或事件数据。这允许较低延迟的处理,并更容易支持多个数据源和分布式数据消耗。与以日志为中心的系统(例如Scribe或Flume)相比,Kafka具有同样出色的性能,由于复制而提供的更强的耐用性保证以及更低的端到端延迟。
流处理
Kafka的许多用户在由多个阶段组成的处理管道中处理数据,其中原始输入数据从Kafka主题中使用,然后进行汇总,充实或以其他方式转换为新主题,以供进一步使用或后续处理。例如,用于推荐新闻文章的处理管道可能会从RSS提要中检索文章内容,并将其发布到“文章”主题中。进一步的处理可能会使该内容规范化或重复数据删除,并将清洗后的文章内容发布到新主题中;最后的处理阶段可能会尝试向用户推荐此内容。这样的处理管道基于各个主题创建实时数据流的图形。从0.10.0.0开始,一个轻量但功能强大的流处理库称为Kafka Streams 可以在Apache Kafka中使用来执行上述数据处理。除了Kafka Streams以外,其他开源流处理工具还包括Apache Storm和 Apache Samza。
活动采集
事件源是一种应用程序,其中状态更改以时间顺序记录记录。Kafka对大量存储的日志数据的支持使其成为以这种样式构建的应用程序的绝佳后端。
提交日志
Kafka可以用作分布式系统的一种外部提交日志。该日志有助于在节点之间复制数据,并充当故障节点恢复其数据的重新同步机制。Kafka中的日志压缩功能有助于支持此用法。在这种用法中,Kafka类似于Apache BookKeeper项目。
集群搭建
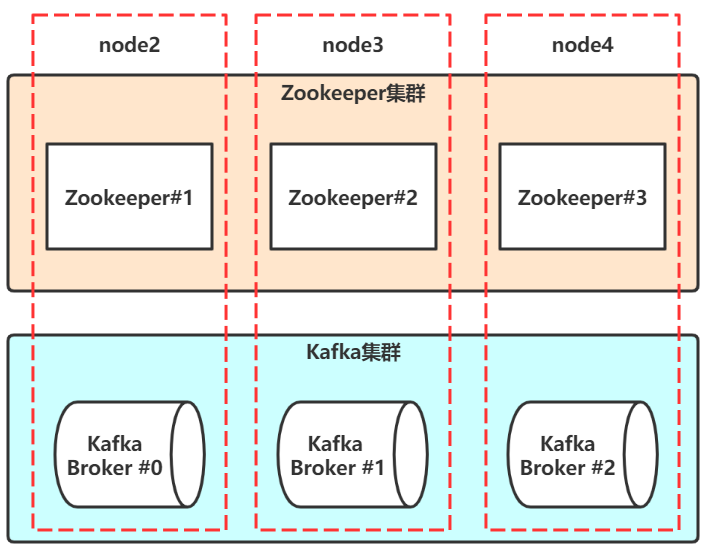
分配三台Linux,用于安装拥有三个节点的Kafka集群:
- node2(192.168.100.102)
- node3(192.168.100.103)
- node4(192.168.100.104)
以上三台主机的/etc/hosts配置:
192.168.100.101 node1
192.168.100.102 node2
192.168.100.103 node3
192.168.100.104 node4ZooKeeper集群搭建
Linux安装JDK,三台Linux都安装。
# 使用rpm安装JDK
rpm -ivh jdk-8u261-linux-x64.rpm
# 默认的安装路径是/usr/java/jdk1.8.0_261-amd64
# 配置JAVA_HOME
vim /etc/profile
# 文件最后添加两行
export JAVA_HOME=/usr/java/jdk1.8.0_261-amd64
export PATH=$PATH:$JAVA_HOME/bin
# 退出vim,使配置生效
source /etc/profile查看JDK是否正确安装
java -version Linux安装ZooKeeper,三台Linux都安装,以搭建ZooKeeper集群。
- 上传zookeeper-3.4.14.tar.gz到Linux
- 解压并配置ZooKeeper
# node2操作
# 解压到/opt目录
tar -zxf zookeeper-3.4.14.tar.gz -C /opt
# 配置
cd /opt/zookeeper-3.4.14/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
# 设置
dataDir=/var/rubin/zookeeper/data
# 添加
server.1=node2:2881:3881
server.2=node3:2881:3881
server.3=node4:2881:3881
# 退出vim
mkdir -p /var/rubin/zookeeper/data
echo 1 > /var/rubin/zookeeper/data/myid
# 配置环境变量
vim /etc/profile
# 添加
export ZOOKEEPER_PREFIX=/opt/zookeeper-3.4.14
export PATH=$PATH:$ZOOKEEPER_PREFIX/bin
export ZOO_LOG_DIR=/var/rubin/zookeeper/log
# 退出vim,让配置生效
source /etc/profile
# 将/opt/zookeeper-3.4.14拷贝到node3,node4
scp -r /opt/zookeeper-3.4.14/ node3:/opt
scp -r /opt/zookeeper-3.4.14/ node4:/optnode3配置
# 配置环境变量
vim /etc/profile
# 在配置JDK环境变量基础上,添加内容
export ZOOKEEPER_PREFIX=/opt/zookeeper-3.4.14
export PATH=$PATH:$ZOOKEEPER_PREFIX/bin
export ZOO_LOG_DIR=/var/rubin/zookeeper/log
# 退出vim,让配置生效
source /etc/profile
mkdir -p /var/rubin/zookeeper/data
echo 2 > /var/rubin/zookeeper/data/myidnode4配置
# 配置环境变量
vim /etc/profile
# 在配置JDK环境变量基础上,添加内容
export ZOOKEEPER_PREFIX=/opt/zookeeper-3.4.14
export PATH=$PATH:$ZOOKEEPER_PREFIX/bin
export ZOO_LOG_DIR=/var/rubin/zookeeper/log
# 退出vim,让配置生效
source /etc/profile
mkdir -p /var/rubin/zookeeper/data
echo 3 > /var/rubin/zookeeper/data/myid启动ZooKeeper
# 在三台Linux上启动ZooKeeper
[root@node2 ~]# zkServer.sh start
[root@node3 ~]# zkServer.sh start
[root@node4 ~]# zkServer.sh start
# 在三台Linux上查看ZooKeeper的状态
[root@node2 ~]# zkServer.sh status
[root@node3 ~]# zkServer.sh status
[root@node4 ~]# zkServer.sh statusKafka集群搭建
安装Kafka
# 解压到/opt
tar -zxf kafka_2.12-1.0.2.tgz -C /opt
# 拷贝到node3和node4
scp -r /opt/kafka_2.12-1.0.2/ node3:/opt
scp -r /opt/kafka_2.12-1.0.2/ node4:/opt配置Kafka
# 配置环境变量,三台Linux都要配置
vim /etc/profile
# 添加以下内容:
export KAFKA_HOME=/opt/kafka_2.12-1.0.2
export PATH=$PATH:$KAFKA_HOME/bin
# 让配置生效
source /etc/profile
# node2配置
vim /opt/kafka_2.12-1.0.2/config/server.properties
broker.id=0
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://node2:9092
log.dirs=/var/rubin/kafka/kafka-logs
zookeeper.connect=node2:2181,node3:2181,node4:2181/myKafka
# 其他使用默认配置
# node3配置
vim /opt/kafka_2.12-1.0.2/config/server.properties
broker.id=1
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://node3:9092
log.dirs=/var/rubin/kafka/kafka-logs
zookeeper.connect=node2:2181,node3:2181,node4:2181/myKafka
# 其他使用默认配置
# node4配置
vim /opt/kafka_2.12-1.0.2/config/server.properties
broker.id=2
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://node4:9092
log.dirs=/var/rubin/kafka/kafka-logs
zookeeper.connect=node2:2181,node3:2181,node4:2181/myKafka
# 其他使用默认配置启动Kafka
[root@node2 ~]# kafka-server-start.sh /opt/kafka_2.12-
1.0.2/config/server.properties
[root@node3 ~]# kafka-server-start.sh /opt/kafka_2.12-
1.0.2/config/server.properties
[root@node4 ~]# kafka-server-start.sh /opt/kafka_2.12-
1.0.2/config/server.properties验证Kafka
node2节点的Cluster Id:

node3节点的Cluster Id:

node4节点的Cluster Id:

- Cluster Id是一个唯一的不可变的标志符,用于唯一标志一个Kafka集群
- 该Id最多可以有22个字符组成,字符对应于URL-safe Base64
- Kafka 0.10.1版本及之后的版本中,在集群第一次启动的时候,Broker从ZooKeeper的/cluster/id节点获取。如果该Id不存在,就自动生成一个新的
zkCli.sh
# 查看每个Broker的信息
get /brokers/ids/0
get /brokers/ids/1
get /brokers/ids/2集群监控
监控度量指标
Kafka使用Yammer Metrics在服务器和Scala客户端中报告指标。Java客户端使用Kafka Metrics,它是一个内置的度量标准注册表,可最大程度地减少拉入客户端应用程序的传递依赖项。两者都通过JMX公开指标,并且可以配置为使用可插拔的统计报告器报告统计信息,以连接到您的监视系统。
具体的监控指标可以查看官方文档。
JMX
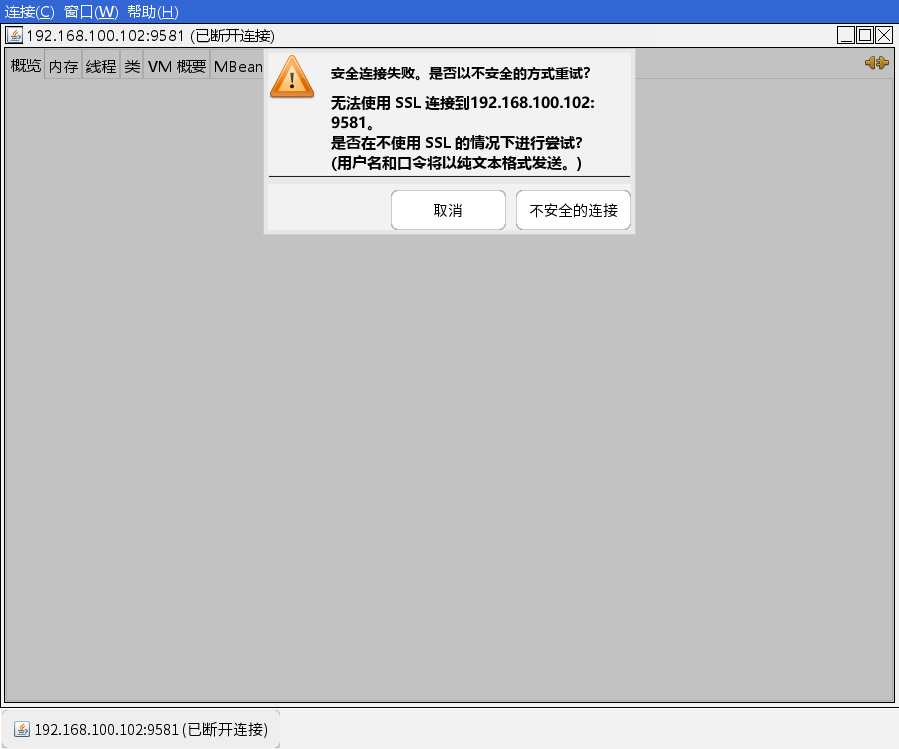
注意:本监控仅限于局域网监控,如果服务器在阿里云上使用公网IP,笔者实验是连接失败的。
Kafka开启Jmx端口
[root@node4 bin]# vim /opt/kafka_2.12-1.0.2/bin/kafka-server-start.sh
所有kafka机器添加一个JMX_PORT,并重启kafka。
验证JMX开启
首先打印9581端口占用的进程信息,然后使用进程编号对应到Kafka的进程号,搞定。
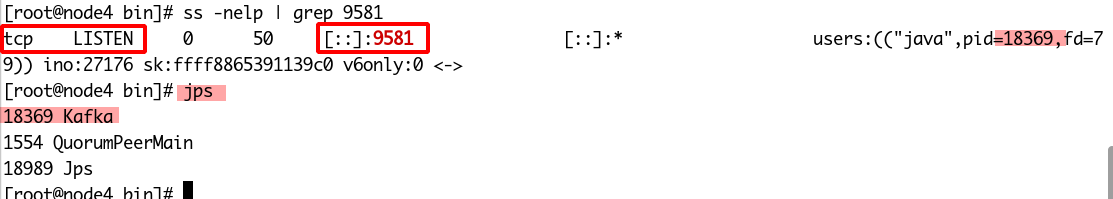
也可以查看Kafka启动日志,确定启动参数-Dcom.sun.management.jmxremote.port=9581存在即可。
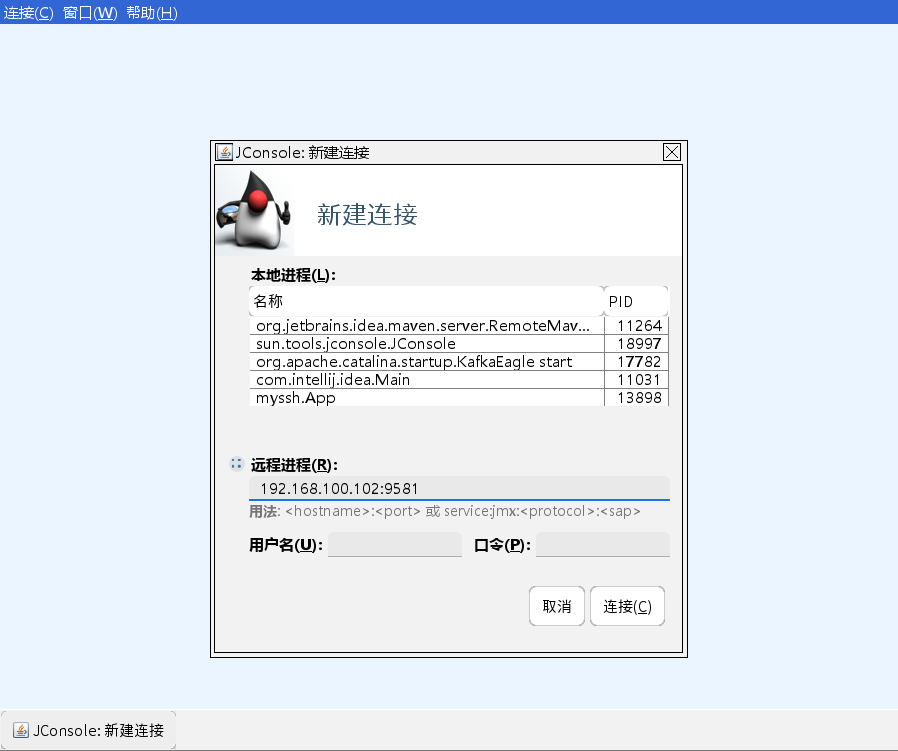
使用JConsole链接JMX端口
win/mac,找到jconsole工具并打开, 在${JAVA_HOEM}/bin/
Mac电脑可以直接命令行输入jconsole。

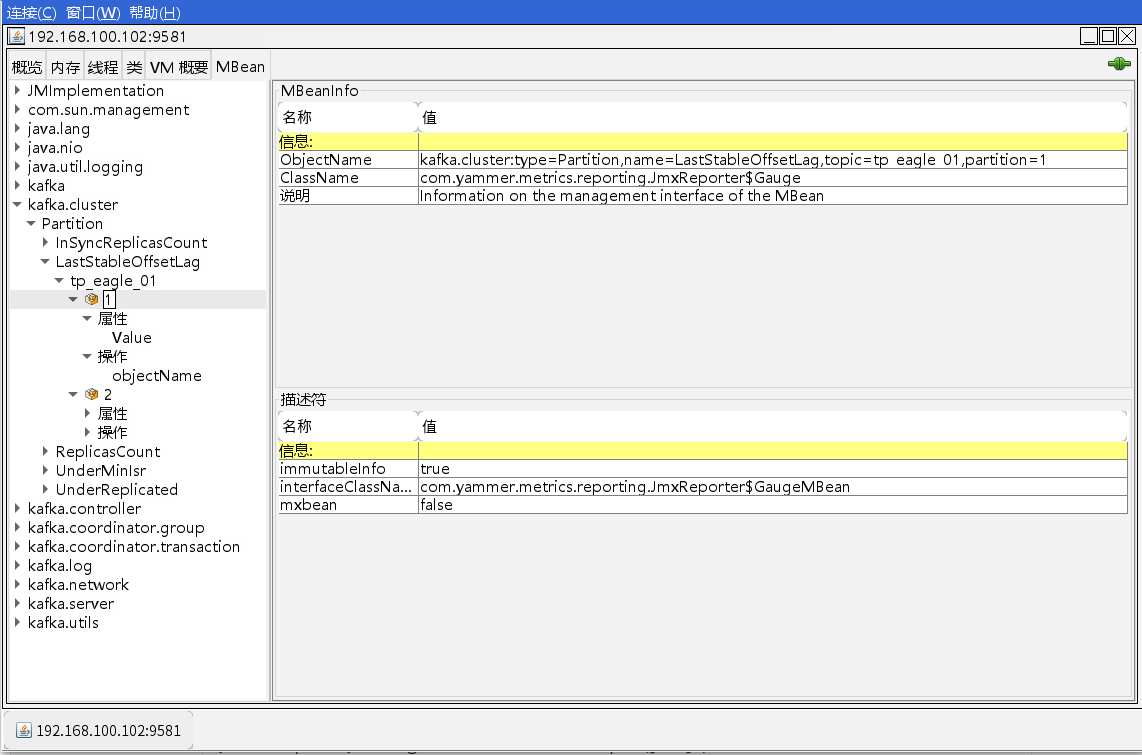
OS监控项
| objectName | 指标项 | 说明 |
| java.lang:type=OperatingSystem | FreePhysicalMemorySize | 空闲物理内存 |
| java.lang:type=OperatingSystem | SystemCpuLoad | 系统CPU利用率 |
| java.lang:type=OperatingSystem | ProcessCpuLoad | 进程CPU利用率 |
| java.lang:type=GarbageCollector, name=G1 Young Generation | CollectionCount | GC次数 |
Broker指标
| objectName | 指标项 | 说明 |
| kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec | Count | 每秒输入的流量 |
| kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec | Count | 每秒输出的流量 |
| kafka.server:type=BrokerTopicMetrics,name=BytesRejectedPerSec | Count | 每秒扔掉的流量 |
| kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec | Count | 每秒的消息写入总量 |
| kafka.server:type=BrokerTopicMetrics,name=FailedFetchRequestsPerSec | Count | 当前机器每秒fetch请求失败的数量 |
| kafka.server:type=BrokerTopicMetrics,name=FailedProduceRequestsPerSec | Count | 当前机器每秒produce请求失败的数量 |
| kafka.server:type=ReplicaManager,name=PartitionCount | Value | 该Broker上的partition的数量 |
| kafka.server:type=ReplicaManager,name=LeaderCount | Value | Leader的replica的数量 |
| kafka.network:type=RequestMetrics,name=TotalTimeMs,request=FetchConsumer | Count | 一个请求FetchConsumer耗费的所有时间 |
| kafka.network:type=RequestMetrics,name=TotalTimeMs,request=FetchFollower | Count | 一个请求FetchFollower耗费的所有时间 |
| kafka.network:type=RequestMetrics,name=TotalTimeMs,request=Produce | Count | 一个请求Produce耗费的所有时间 |
Producer以及Topic指标
| objectName | 指标项 | 官网说明 | 译文说明 |
| kafka.producer:type=producer-metrics,client-id=console-producer(client-id会变化) | incoming- byte-rate | The average number of incoming bytes received per second from all servers. | Producer 每秒的平均 写入流量 |
| kafka.producer:type=producer-metrics,client-id=console-producer(client-id会变化) | outgoing- byte-rate | The average number of outgoing bytes sent per second to all servers. | Producer 每秒的输出 流量 |
| kafka.producer:type=producer-metrics,client-id=console-producer(client-id会变化) | request- rate | The average number of requests sent per second to the broker. | Producer 每秒发给 broker的平 均request 次数 |
| kafka.producer:type=producer-metrics,client-id=console-producer(client-id会变化) | response- rate | The average number of responses received per second from the broker. | Producer 每秒发给 broker的平 均 response 次数 |
| kafka.producer:type=producer-metrics,client-id=console-producer(client-id会变化) | request- latency- avg | The average time taken for a fetch request. | 一个fetch 请求的平均 时间 |
| kafka.producer:type=producer-topic-metrics,client-id=console-producer,topic=testjmx(client-id和topic名称会变化) | record- send-rate | The average number of records sent per second for a topic. | 每秒从 topic发送 的平均记录 数 |
| kafka.producer:type=producer-topic-metrics,client-id=console-producer,topic=testjmx(client-id和topic名称会变化) | record- retry-total | The total number of retried record sends | 重试发送的 消息总数量 |
| kafka.producer:type=producer-topic-metrics,client-id=console-producer,topic=testjmx(client-id和topic名称会变化) | record- error- total | The total number of record sends that resulted in errors | 发送错误的 消息总数量 |
Consumer指标
| objectName | 指标项 | 官网说明 | 说明 |
| kafka.consumer:type=consumer-fetch-manager-metrics,client-id=consumer-1(client-id会变化) | records- lag-max | Number of messages the consumer lags behind the producer by. Published by the consumer, not broker. | 由 Consumer 提交的消 息消费lag |
| kafka.consumer:type=consumer-fetch-manager-metrics,client-id=consumer-1(client-id会变化) | records- consumed- rate | The average number of records consumed per second | 每秒平均 消费的消 息数量 |
编程手段来获取监控指标
package com.rubin.kafka.jmx;
import javax.management.*;
import javax.management.remote.JMXConnector;
import javax.management.remote.JMXConnectorFactory;
import javax.management.remote.JMXServiceURL;
import java.io.IOException;
import java.util.Iterator;
import java.util.Set;
public class JMXMonitorDemo {
public static void main(String[] args) throws IOException, MalformedObjectNameException, AttributeNotFoundException, MBeanException, ReflectionException, InstanceNotFoundException {
String jmxServiceURL = "service:jmx:rmi:///jndi/rmi://kafka-host:9581/jmxrmi";
JMXServiceURL jmxURL = null;
JMXConnector jmxc = null;
MBeanServerConnection jmxs = null;
ObjectName mbeanObjName = null;
Iterator sampleIter = null;
Set sampleSet = null;
// 创建JMXServiceURL对象,参数是
jmxURL = new JMXServiceURL(jmxServiceURL);
// 建立到指定URL服务器的连接
jmxc = JMXConnectorFactory.connect(jmxURL);
// 返回代表远程MBean服务器的MBeanServerConnection对象
jmxs = jmxc.getMBeanServerConnection();
// 根据传入的字符串,创建ObjectName对象
// mbeanObjName = new ObjectName("kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec");
// mbeanObjName = new ObjectName("kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec,topic=tp_eagle_01");
mbeanObjName = new ObjectName("kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec");
// 获取指定ObjectName对应的MBeans
sampleSet = jmxs.queryMBeans(null, mbeanObjName);
// 迭代器
sampleIter = sampleSet.iterator();
if (sampleSet.isEmpty()) {
} else {
// 如果返回了,则打印信息
while (sampleIter.hasNext()) {
// Used to represent the object name of an MBean and its class name.
// If the MBean is a Dynamic MBean the class name should be retrieved from the MBeanInfo it provides.
// 用于表示MBean的ObjectName和ClassName
ObjectInstance sampleObj = (ObjectInstance) sampleIter.next();
ObjectName objectName = sampleObj.getObjectName();
// 查看指定MBean指定属性的值
String count = jmxs.getAttribute(objectName, "Count").toString();
System.out.println(count);
}
}
// 关闭
jmxc.close();
}
}
监控工具Kafka Eagle
我们可以使用Kafka-eagle管理Kafka集群。
核心模块:
- 面板可视化
- 主题管理,包含创建主题、删除主题、主题列举、主题配置、主题查询等
- 消费者应用:对不同消费者应用进行监控,包含Kafka API、Flink API、Spark API、Storm API、Flume API、LogStash API等
- 集群管理:包含对Kafka集群和Zookeeper集群的详情展示,其内容包含Kafka启动时间。Kafka端口号、Zookeeper Leader角色等。同时,还有多集群切换管理,Zookeeper Client操作入口
- 集群监控:包含对Broker、Kafka核心指标、Zookeeper核心指标进行监控,并绘制历史趋势图
- 告警功能:对消费者应用数据积压情况进行告警,以及对Kafka和Zookeeper监控度进行告警。同时,支持邮件、微信、钉钉告警通知
- 系统管理:包含用户创建、用户角色分配、资源访问进行管理
架构:
- 可视化:负责展示主题列表、集群健康、消费者应用等
- 采集器:数据采集的来源包含Zookeeper、Kafka JMX & 内部Topic、Kafka API(Kafka 2.x以后版本)
- 数据存储:目前Kafka Eagle存储采用MySQL或SQLite,数据库和表的创建均是自动完成的,按照官方文档进行配置好,启动Kafka Eagle就会自动创建,用来存储元数据和监控数据
- 监控:负责见消费者应用消费情况、集群健康状态
- 告警:对监控到的异常进行告警通知,支持邮件、微信、钉钉等方式
- 权限管理:对访问用户进行权限管理,对于管理员、开发者、访问者等不同角色的用户,分配不用的访问权限
需要Kafka节点开启JMX。
搭建过程
# 下载编译好的包
wget http://pkgs-linux.cvimer.com/kafka-eagle.zip
# 配置kafka-eagle
unzip kafka-eagle.zip
cd kafka-eagle/kafka-eagle-web/target
mkdir -p test
cp kafka-eagle-web-2.0.1-bin.tar.gz test/
tar xf kafka-eagle-web-2.0.1-bin.tar.gz
cd kafka-eagle-web-2.0.1需要配置环境变量:
KE_HOME=XXX
PATH=XXXconf下的配置文件:system-config.properties
######################################
# multi zookeeper & kafka cluster list
######################################
# 集群的别名,用于在kafka-eagle中进行区分。
# 可以配置监控多个集群,别名用逗号隔开
# kafka.eagle.zk.cluster.alias=cluster1,cluster2,cluster3
kafka.eagle.zk.cluster.alias=cluster1
# cluster1.zk.list=10.1.201.17:2181,10.1.201.22:2181,10.1.201.23:2181
# 配置当前集群的zookeeper地址,此处的值要与Kafka的server.properties中的
zookeeper.connect的值一致
# 此处的前缀就是集群的别名
cluster1.zk.list=node2:2181,node3:2181,node4:2181/myKafka
#cluster2.zk.list=xdn10:2181,xdn11:2181,xdn12:2181
######################################
# zookeeper enable acl
######################################
cluster1.zk.acl.enable=false
cluster1.zk.acl.schema=digest
cluster1.zk.acl.username=test
cluster1.zk.acl.password=test123
######################################
# broker size online list
######################################
cluster1.kafka.eagle.broker.size=20
######################################
# zookeeper客户端连接数限制
######################################
kafka.zk.limit.size=25
######################################
# kafka eagle网页端口号
######################################
kafka.eagle.webui.port=8048
######################################
# kafka 消费信息存储位置,用来兼容kafka低版本
######################################
cluster1.kafka.eagle.offset.storage=kafka
cluster2.kafka.eagle.offset.storage=zk
######################################
# kafka metrics, 15 days by default
######################################
kafka.eagle.metrics.charts=true
kafka.eagle.metrics.retain=15
######################################
# kafka sql topic records max
######################################
kafka.eagle.sql.topic.records.max=5000
kafka.eagle.sql.fix.error=true
######################################
# 管理员删除kafka中topic的口令
######################################
kafka.eagle.topic.token=keadmin
######################################
# kafka 集群是否开启了认证模式,此处是cluster1集群的配置,禁用
######################################
cluster1.kafka.eagle.sasl.enable=false
cluster1.kafka.eagle.sasl.protocol=SASL_PLAINTEXT
cluster1.kafka.eagle.sasl.mechanism=SCRAM-SHA-256
cluster1.kafka.eagle.sasl.jaas.config=org.apache.kafka.common.security.scra
m.ScramLoginModule required username="kafka" password="kafka-eagle";
cluster1.kafka.eagle.sasl.client.id=
cluster1.kafka.eagle.sasl.cgroup.enable=false
cluster1.kafka.eagle.sasl.cgroup.topics=
######################################
# kafka ssl authenticate,示例配置
######################################
cluster2.kafka.eagle.sasl.enable=false
cluster2.kafka.eagle.sasl.protocol=SASL_PLAINTEXT
cluster2.kafka.eagle.sasl.mechanism=PLAIN
cluster2.kafka.eagle.sasl.jaas.config=org.apache.kafka.common.security.plai
n.PlainLoginModule required username="kafka" password="kafka-eagle";
cluster2.kafka.eagle.sasl.client.id=
cluster2.kafka.eagle.sasl.cgroup.enable=false
cluster2.kafka.eagle.sasl.cgroup.topics=
######################################
# kafka ssl authenticate,示例配置
######################################
cluster3.kafka.eagle.ssl.enable=false
cluster3.kafka.eagle.ssl.protocol=SSL
cluster3.kafka.eagle.ssl.truststore.location=
cluster3.kafka.eagle.ssl.truststore.password=
cluster3.kafka.eagle.ssl.keystore.location=
cluster3.kafka.eagle.ssl.keystore.password=
cluster3.kafka.eagle.ssl.key.password=
cluster3.kafka.eagle.ssl.cgroup.enable=false
cluster3.kafka.eagle.ssl.cgroup.topics=
######################################
# 存储监控数据的数据库地址
# kafka默认使用sqlite存储,需要指定和创建sqlite的目录
# 如 /home/rubin/hadoop/kafka-eagle/db
######################################
kafka.eagle.driver=org.sqlite.JDBC
kafka.eagle.url=jdbc:sqlite:/home/rubin/hadoop/kafka-eagle/db/ke.db
kafka.eagle.username=root
kafka.eagle.password=www.kafka-eagle.org
######################################
# 还可以使用MySLQ存储监控数据
######################################
#kafka.eagle.driver=com.mysql.jdbc.Driver
#kafka.eagle.url=jdbc:mysql://127.0.0.1:3306/ke?
useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
#kafka.eagle.username=root
#kafka.eagle.password=123456
######################################
# kafka eagle 设置告警邮件服务器
######################################
kafka.eagle.mail.enable=true
kafka.eagle.mail.sa=kafka_rubin_alert
kafka.eagle.mail.username=kafka_rubin_alert@163.com
kafka.eagle.mail.password=Pas2W0rd
kafka.eagle.mail.server.host=smtp.163.com
kafka.eagle.mail.server.port=25也可以自行编译, https://github.com/smartloli/kafka-eagle。
创建Eagel的存储目录: mkdir -p /hadoop/kafka-eagle
# 启动kafka-eagle
./bin/ke.sh start会提示我们登陆地址和账号密码。
账号密码为:admin/123456。
本文的内容至此就结束了。欢迎小伙伴们积极留言交流~~~
附件
链接:https://pan.baidu.com/s/1f4LzpE4XowwbHqlwHs8GSw
提取码:ejr2

文章评论