AtomicInteger和AtomicLong
如下面代码所示,对于一个整数的加减操作,要保证线程安全,需要加锁,也就是加synchronized关键字。
public class MyClass {
private int count = 0;
public void synchronized increment() {
count++;
}
public void synchronized decrement() {
count--;
}
}但有了Concurrent包的Atomic相关的类之后,synchronized关键字可以用AtomicInteger代替,其性能更好,对应的代码变为:
public class MyClass {
private AtomicInteger count = new AtomicInteger(0);
public void add() {
count.getAndIncrement();
}
public long minus() {
count.getAndDecrement();
}
}其对应的源码如下:
/**
* Atomically increments by one the current value.
*
* @return the previous value
*/
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
/**
* Atomically decrements by one the current value.
*
* @return the previous value
*/
public final int getAndDecrement() {
return unsafe.getAndAddInt(this, valueOffset, -1);
}上面代码中的unsafe是Unsafe的对象:
// setup to use Unsafe.compareAndSwapInt for updates
private static final Unsafe unsafe = Unsafe.getUnsafe();AtomicInteger的getAndIncrement()方法和getAndDecrement()方法都调用了一个方法:unsafe.getAndAddInt(…)方法,该方法基于CAS实现:
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}do-while循环直到判断条件返回true为止。该操作称为自旋。
public native int getIntVolatile(Object var1, long var2);getAndAddInt方法具有volatile的语义,也就是对所有线程都是同时可见的。
上述中的方法中:
- 第一个参数表示要修改哪个对象的属性值
- 第二个参数是该对象属性在内存的偏移量
- 第三个参数表示期望值
- 第四个参数表示要设置为的目标值
源码比较简单,重要的是其中的设计思想。
除AtomicInteger,AtomicLong也是同样的原理,就不展开详述了。
AtomicBoolean和AtomicReference
为什么需要AtomicBoolean
对于int或者long型变量,需要进行加减操作,所以要加锁;但对于一个boolean类型来说,true或false的赋值和取值操作,加上volatile关键字就够了,为什么还需要AtomicBoolean呢?
这是因为往往要实现下面这种功能:
if (!flag) {
flag = true;
// ...
}
// 或者更清晰一点的:
if (flag == false) {
flag = true;
// ...
}也就是要实现compare和set两个操作合在一起的原子性,而这也正是CAS提供的功能。上面的代码,就变成:
if (compareAndSet(false, true)) {
// ...
}同样地,AtomicReference也需要同样的功能,对应的方法如下:
/**
* Atomically sets the value to the given updated value
* if the current value {@code ==} the expected value.
* @param expect the expected value
* @param update the new value
* @return {@code true} if successful. False return indicates that
* the actual value was not equal to the expected value.
*/
public final boolean compareAndSet(V expect, V update) {
return unsafe.compareAndSwapObject(this, valueOffset, expect, update);
}其中,expect是旧的引用,update为新的引用。
如何支持boolean和double类型
在Unsafe类中,只提供了三种类型的CAS操作:int、long、Object(也就是引用类型)。如下所示:



即,在jdk的实现中,这三种CAS操作都是由底层实现的,其他类型的CAS操作都要转换为这三种之一进行操作。
其中的参数:
- 第一个参数是要修改的对象
- 第二个参数是对象的成员变量在内存中的位置(一个long型的整数)
- 第三个参数是该变量的旧值
- 第四个参数是该变量的新值
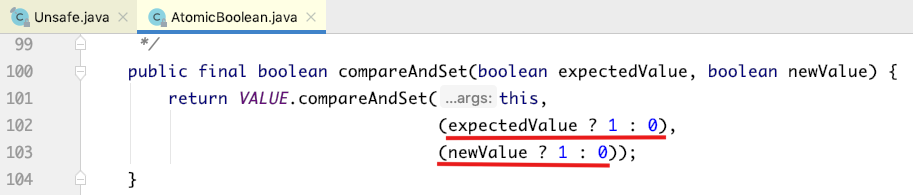
AtomicBoolean类型如何支持?
对于用int型来代替的,在入参的时候,将boolean类型转换成int类型;在返回值的时候,将int类型转换成boolean类型。如下所示:
如果是double类型,又如何支持呢?
这依赖double类型提供的一对double类型和long类型互转的方法:


Unsafe类中的方法实现:

AtomicStampedReference和AtomicMarkableReference
ABA问题与解决办法
到目前为止,CAS都是基于“值”来做比较的。但如果另外一个线程把变量的值从A改为B,再从B改回到A,那么尽管修改过两次,可是在当前线程做CAS操作的时候,却会因为值没变而认为数据没有被其他线程修改过,这就是所谓的ABA问题。
要解决ABA问题,不仅要比较“值”,还要比较“版本号”,而这正是AtomicStampedReference做的事情,其对应的CAS方法如下:

之前的 CAS只有两个参数,这里的 CAS有四个参数,后两个参数就是版本号的旧值和新值。
当expectedReference != 对象当前的reference时,说明该数据肯定被其他线程修改过。
当expectedReference == 对象当前的reference时,再进一步比较expectedStamp是否等于对象当前的版本号,以此判断数据是否被其他线程修改过。
为什么没有AtomicStampedInteger或AtomictStampedLong
要解决Integer或者Long型变量的ABA问题,为什么只有AtomicStampedReference,而没有AtomicStampedInteger或者AtomictStampedLong呢?
因为这里要同时比较数据的“值”和“版本号”,而Integer型或者Long型的CAS没有办法同时比较两个变量。
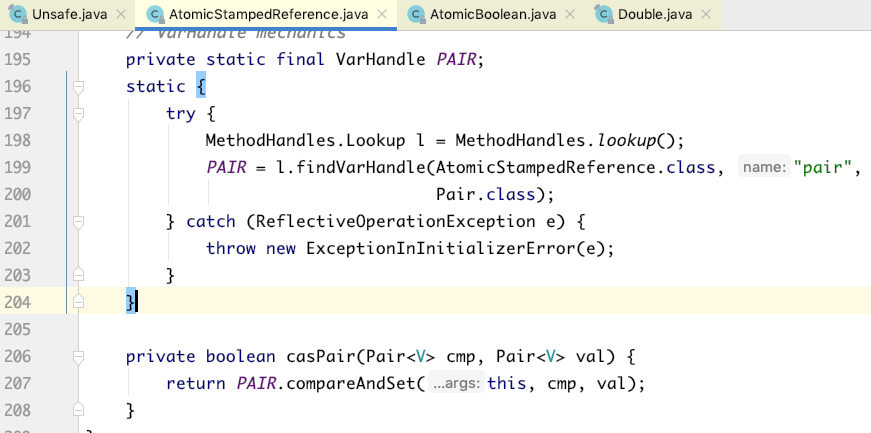
于是只能把值和版本号封装成一个对象,也就是这里面的Pair内部类,然后通过对象引用的CAS来实现。代码如下所示:

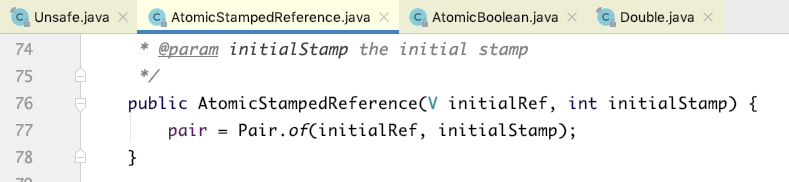
当使用的时候,在构造方法里面传入值和版本号两个参数,应用程序对版本号进行累加操作,然后调用上面的CAS。如下所示:
AtomicMarkableReference
AtomicMarkableReference与AtomicStampedReference原理类似,只是Pair里面的版本号是boolean类型的,而不是整型的累加变量,如下所示:

因为是boolean类型,只能有true、false两个版本号,所以并不能完全避免ABA问题,只是降低了ABA发生的概率。
AtomicIntegerFieldUpdater、AtomicLongFieldUpdater和AtomicReferenceFieldUpdater
为什么需要AtomicXXXFieldUpdater
如果一个类是自己编写的,则可以在编写的时候把成员变量定义为Atomic类型。但如果是一个已经有的类,在不能更改其源代码的情况下,要想实现对其成员变量的原子操作,就需要AtomicIntegerFieldUpdater、AtomicLongFieldUpdater和AtomicReferenceFieldUpdater。
通过AtomicIntegerFieldUpdater理解它们的实现原理。
AtomicIntegerFieldUpdater是一个抽象类。
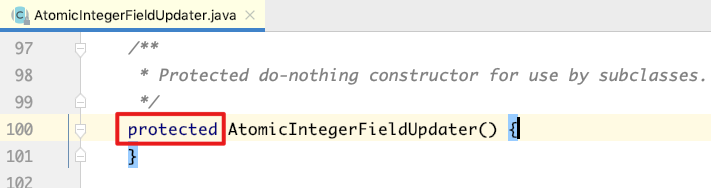
首先,其构造方法是protected,不能直接构造其对象,必须通过它提供的一个静态方法来创建,如下所示:
方法newUpdater用于创建AtomicIntegerFieldUpdater类对象:
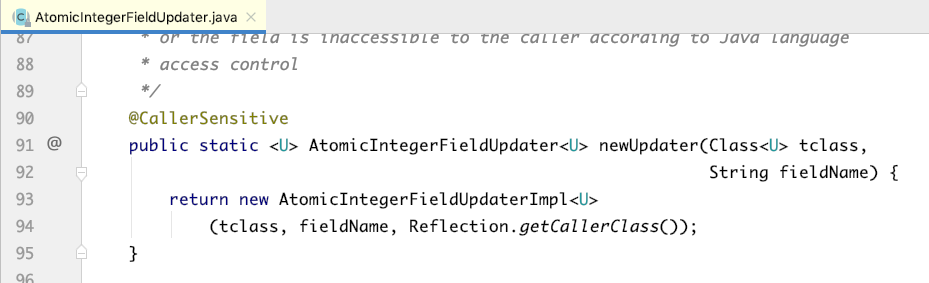
newUpdater(…)静态方法传入的是要修改的类(不是对象)和对应的成员变量的名字,内部通过反射拿到这个类的成员变量,然后包装成一个AtomicIntegerFieldUpdater对象。所以,这个对象表示的是类的某个成员,而不是对象的成员变量。
若要修改某个对象的成员变量的值,再传入相应的对象,如下所示:
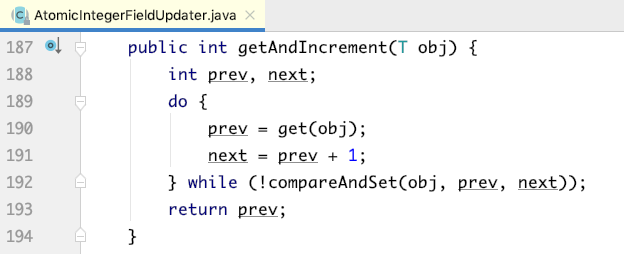

accecssCheck方法的作用是检查该obj是不是tclass类型,如果不是,则拒绝修改,抛出异常。
从代码可以看到,其CAS原理和AtomictInteger是一样的,底层都调用了Unsafe的compareAndSetInt(…)方法。
限制条件
要想使用AtomicIntegerFieldUpdater修改成员变量,成员变量必须是volatile的int类型(不能是Integer包装类),该限制从其构造方法中可以看到:
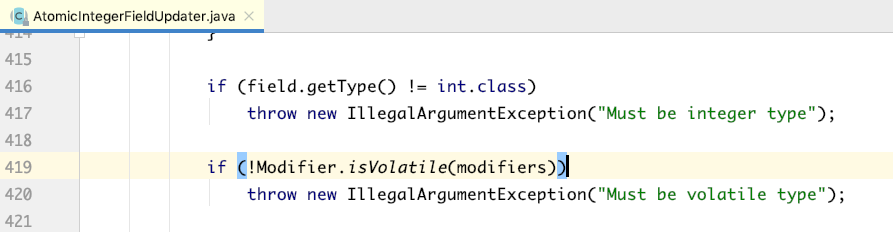
至于AtomicLongFieldUpdater、AtomicReferenceFieldUpdater,也有类似的限制条件。其底层的CAS原理,也和AtomicLong、AtomicReference一样。
AtomicIntegerArray、AtomicLongArray和AtomicReferenceArray
Concurrent包提供了AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray三个数组元素的原子操作。注意,这里并不是说对整个数组的操作是原子的,而是针对数组中一个元素的原子操作而言。
使用方式
以AtomicIntegerArray为例,其使用方式如下:

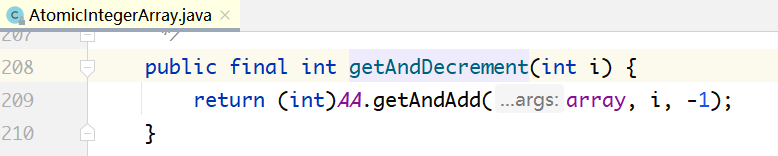
相比于AtomicInteger的getAndIncrement()方法,这里只是多了一个传入参数:数组的下标i。
其他方法也与此类似,相比于AtomicInteger的各种加减方法,也都是多一个下标 i,如下所示:



实现原理
其底层的CAS方法直接调用VarHandle中native的getAndAdd方法。如下所示:
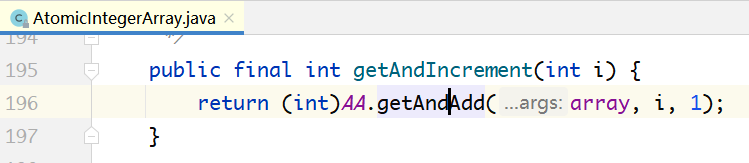

明白了AtomicIntegerArray的实现原理,另外两个数组的原子类实现原理与之类似。
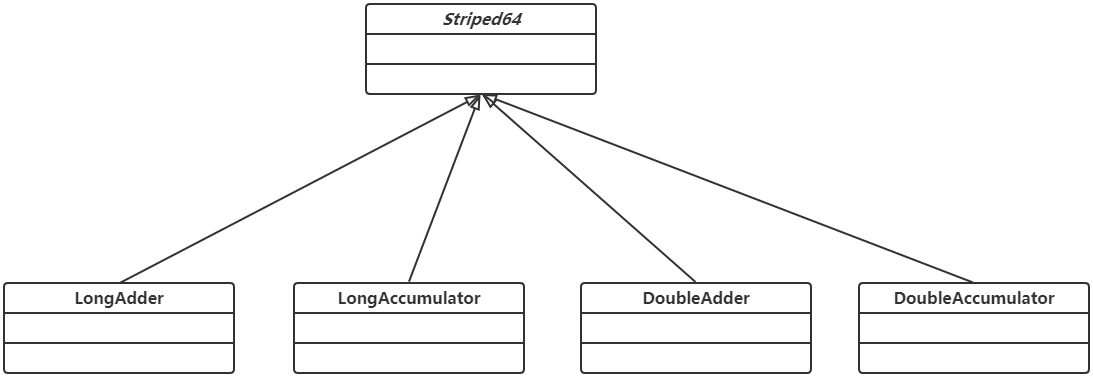
Striped64与LongAdder
从JDK 8开始,针对Long型的原子操作,Java又提供了LongAdder、LongAccumulator;针对Double类型,Java提供了DoubleAdder、DoubleAccumulator。Striped64相关的类的继承层次如下图所示:
LongAdder原理
AtomicLong内部是一个volatile long型变量,由多个线程对这个变量进行CAS操作。多个线程同时对一个变量进行CAS操作,在高并发的场景下仍不够快,如果再要提高性能,该怎么做呢?
把一个变量拆成多份,变为多个变量,有些类似于ConcurrentHashMap的分段锁的例子。如下图所示,把一个Long型拆成一个base变量外加多个Cell,每个Cell包装了一个Long型变量。当多个线程并发累加的时候,如果并发度低,就直接加到base变量上;如果并发度高,冲突大,平摊到这些Cell上。在最后取值的时候,再把base和这些Cell求sum运算。

以LongAdder的sum()方法为例,如下所示:
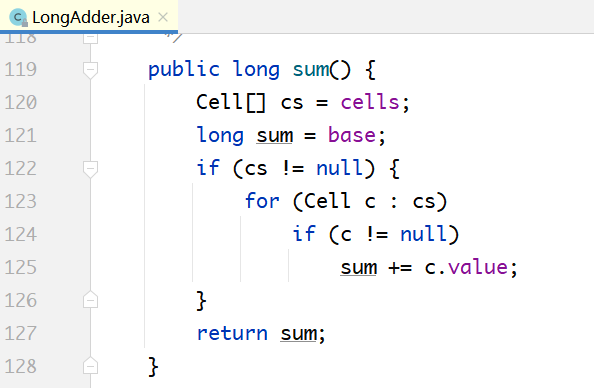
由于无论是long,还是double,都是64位的。但因为没有double型的CAS操作,所以是通过把double型转化成long型来实现的。所以,上面的base和cell[]变量,是位于基类Striped64当中的。英文Striped意为“条带”,也就是分片。
abstract class Striped64 extends Number {
transient volatile Cell[] cells;
transient volatile long base;
@jdk.internal.vm.annotation.Contended static final class Cell {
// ...
volatile long value;
Cell(long x) { value = x; }
// ...
}
}最终一致性
在sum求和方法中,并没有对cells[]数组加锁。也就是说,一边有线程对其执行求和操作,一边还有线程修改数组里的值,也就是最终一致性,而不是强一致性。这也类似于ConcurrentHashMap中的clear()方法,一边执行清空操作,一边还有线程放入数据,clear()方法调用完毕后再读取,hash map里面可能还有元素。因此,在LongAdder适合高并发的统计场景,而不适合要对某个Long 型变量进行严格同步的场景。
伪共享与缓存行填充
在Cell类的定义中,用了一个独特的注解@sun.misc.Contended,这是JDK 8之后才有的,背后涉及一个很重要的优化原理:伪共享与缓存行填充。

每个CPU都有自己的缓存。缓存与主内存进行数据交换的基本单位叫Cache Line(缓存行)。在64位x86架构中,缓存行是64字节,也就是8个Long型的大小。这也意味着当缓存失效,要刷新到主内存的时候,最少要刷新64字节。
如下图所示,主内存中有变量X、Y、Z(假设每个变量都是一个Long型),被CPU1和CPU2分别读入自己的缓存,放在了同一行Cache Line里面。当CPU1修改了X变量,它要失效整行Cache Line,也就是往总线上发消息,通知CPU 2对应的Cache Line失效。由于Cache Line是数据交换的基本单位,无法只失效X,要失效就会失效整行的Cache Line,这会导致Y、Z变量的缓存也失效。
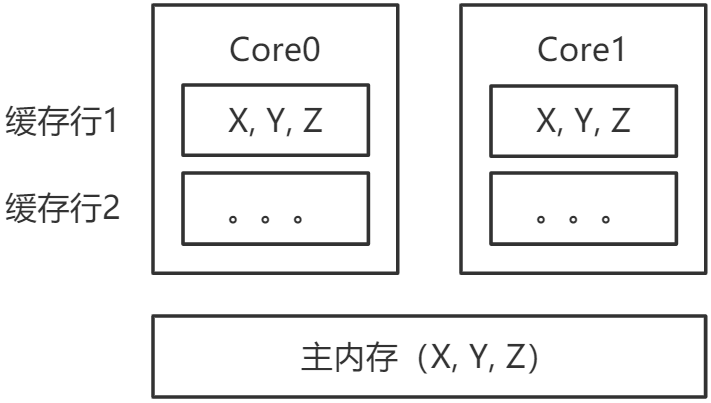
虽然只修改了X变量,本应该只失效X变量的缓存,但Y、Z变量也随之失效。Y、Z变量的数据没有修改,本应该很好地被CPU1和CPU2共享,却没做到,这就是所谓的“伪共享问题”。
问题的原因是,Y、Z和X变量处在了同一行Cache Line里面。要解决这个问题,需要用到所谓的“缓存行填充”,分别在X、Y、Z后面加上7个无用的Long型,填充整个缓存行,让X、Y、Z处在三行不同的缓存行中,如下图所示:
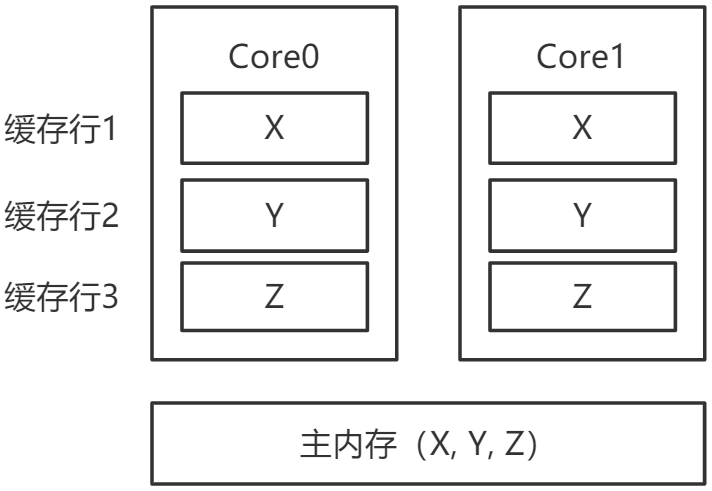
声明一个@jdk.internal.vm.annotation.Contended即可实现缓存行的填充。之所以这个地方要用缓存行填充,是为了不让Cell[]数组中相邻的元素落到同一个缓存行里。
LongAdder核心实现
下面来看LongAdder最核心的累加方法add(long x),自增、自减操作都是通过调用该方法实现的。
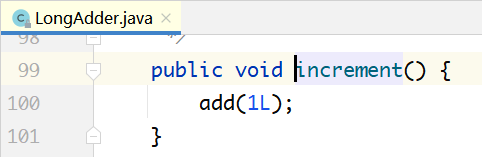
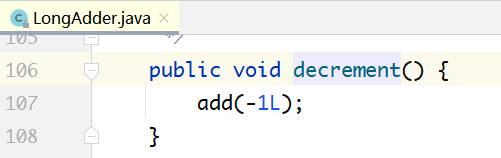
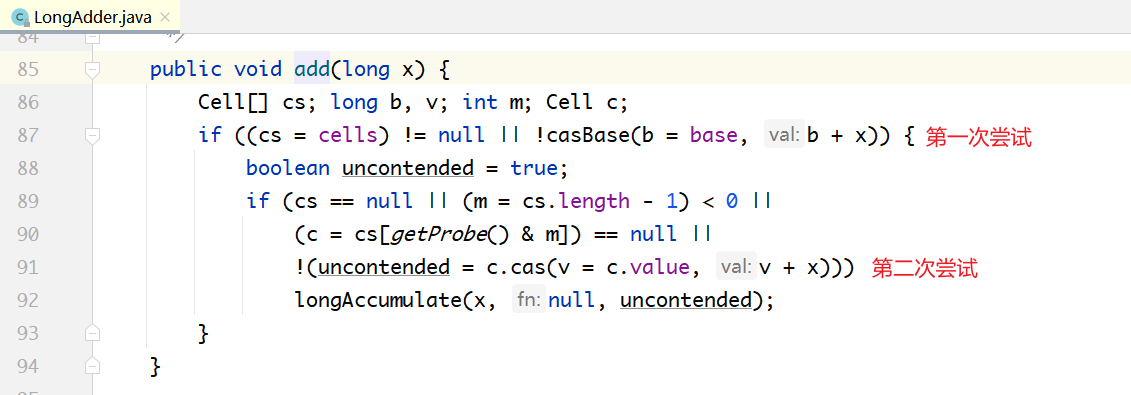
当一个线程调用add(x)的时候,首先会尝试使用casBase把x加到base变量上。如果不成功,则再用c.cas(…)方法尝试把x加到Cell数组的某个元素上。如果还不成功,最后再调用longAccumulate(…)方法。
注意:Cell[]数组的大小始终是2的整数次方,在运行中会不断扩容,每次扩容都是增长2倍。上面代码中的 cs[getProbe() & m] 其实就是对数组的大小取模。因为m=cs.length–1,getProbe()为该线程生成一个随机数,用该随机数对数组的长度取模。因为数组长度是2的整数次方,所以可以用&操作来优化取模运算。
对于一个线程来说,它并不在意到底是把x累加到base上面,还是累加到Cell[]数组上面,只要累加成功就可以。因此,这里使用随机数来实现Cell的长度取模。
如果两次尝试都不成功,则调用longAccumulate(…)方法,该方法在Striped64里面LongAccumulator也会用到,如下所示:
/**
* Handles cases of updates involving initialization, resizing,
* creating new Cells, and/or contention. See above for
* explanation. This method suffers the usual non-modularity
* problems of optimistic retry code, relying on rechecked sets of
* reads.
*
* @param x the value
* @param fn the update function, or null for add (this convention
* avoids the need for an extra field or function in LongAdder).
* @param wasUncontended false if CAS failed before call
*/
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
for (;;) {
Cell[] as; Cell a; int n; long v;
if ((as = cells) != null && (n = as.length) > 0) {
if ((a = as[(n - 1) & h]) == null) {
if (cellsBusy == 0) { // Try to attach new Cell
Cell r = new Cell(x); // Optimistically create
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try { // Recheck under lock
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
collide = false;
}
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
else if (n >= NCPU || cells != as)
collide = false; // At max size or stale
else if (!collide)
collide = true;
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) { // Expand table unless stale
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = advanceProbe(h);
}
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}LongAccumulator
LongAccumulator的原理和LongAdder类似,只是功能更强大,下面为两者构造方法的对比:


LongAdder只能进行累加操作,并且初始值默认为0;LongAccumulator可以自己定义一个二元操作符,并且可以传入一个初始值。
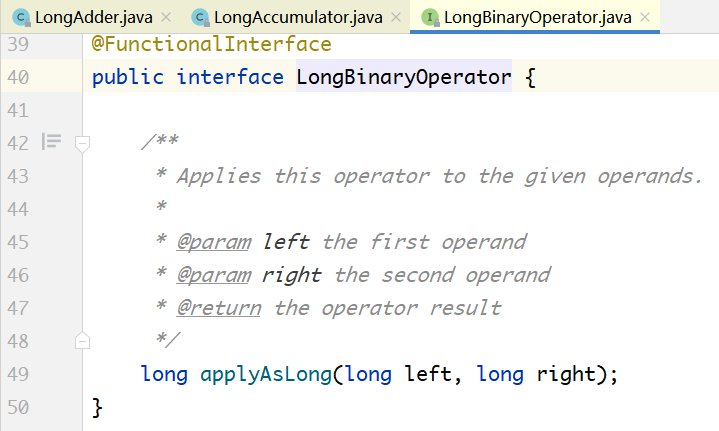
操作符的左值,就是base变量或者Cells[]中元素的当前值;右值,就是add()方法传入的参数x。
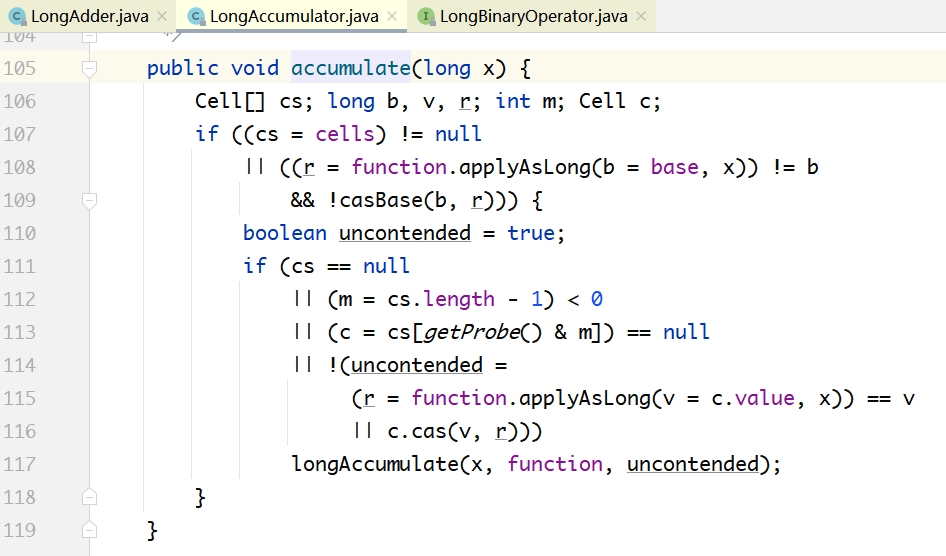
下面是LongAccumulator的accumulate(x)方法,与LongAdder的add(x)方法类似,最后都是调用的Striped64的LongAccumulate(…)方法。
唯一的差别就是LongAdder的add(x)方法调用的是casBase(b, b+x),这里调用的是casBase(b, r),其中,r=function.applyAsLong(b=base, x)。
DoubleAdder与DoubleAccumulator
DoubleAdder其实也是用long型实现的,因为没有double类型的CAS方法。下面是DoubleAdder的add(x)方法,和LongAdder的add(x)方法基本一样,只是多了long和double类型的相互转换。
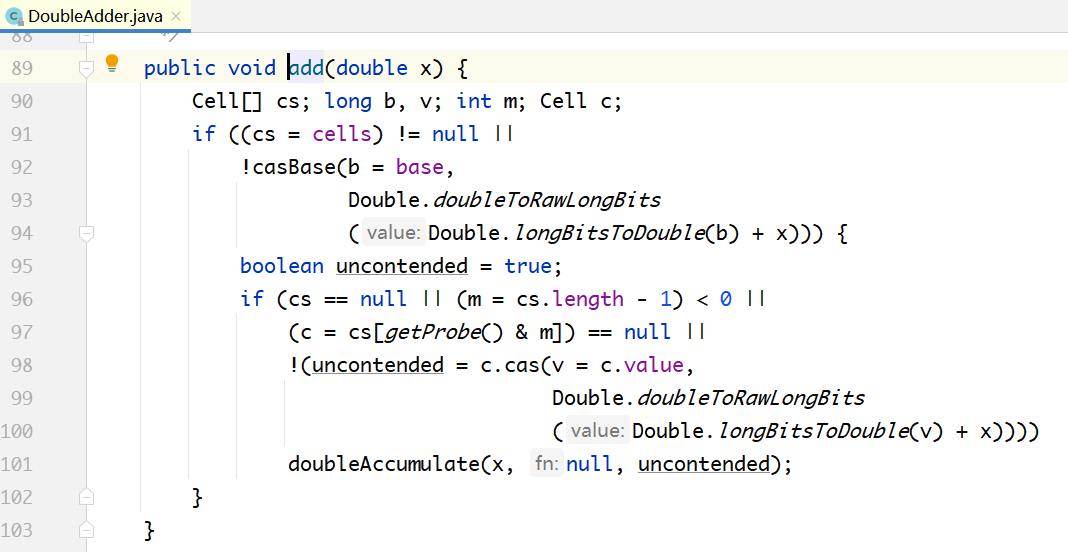
其中的关键Double.doubleToRawLongBits(Double.longBitsToDouble(b) + x),在读出来的时候,它把long类型转换成 double类型,然后进行累加,累加的结果再转换成long类型,通过CAS写回去。
DoubleAccumulate也是Striped64的成员方法,和longAccumulate类似,也是多了long类型和double类型的互相转换。
DoubleAccumulator和DoubleAdder的关系,与LongAccumulator和LongAdder的关系类似,只是多了一个二元操作符。
以上就是本文的全部内容。欢迎小伙伴们积极留言交流~~~

文章评论