索引文档写入和近实时搜索原理
基本概念
Segments in Lucene
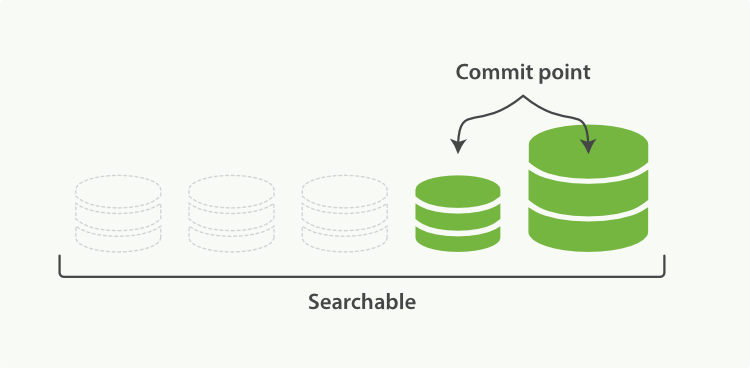
众所周知,Elasticsearch存储的基本单元是Shard ,ES 中一个Index可能分为多个Shard, 事实上每个Shard都是一个 Lucence的Index,并且每个Lucence Index由多个Segment组成, 每个Segment事实上是一些倒排索引的集合, 每次创建一个新的Document, 都会归属于一个新的Segment,而不会去修改原来的Segment。且每次的文档删除操作,会仅仅标记Segment中该文档为删除状态,而不会真正的立马物理删除,所以说ES的Index可以理解为一个抽象的概念。 就像下图所示:
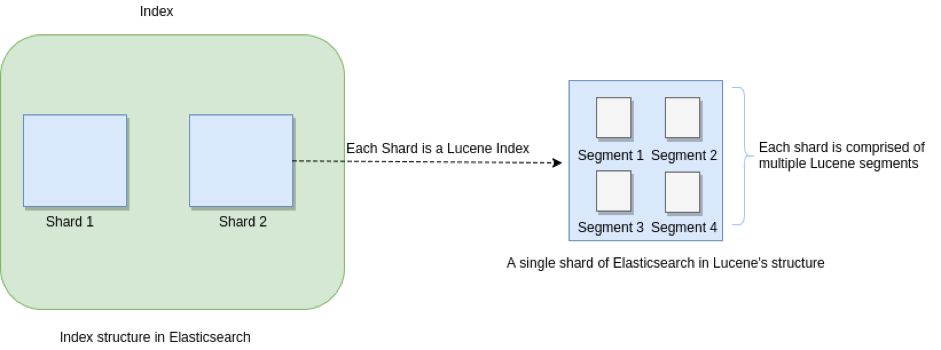
Commits in Lucene
Commit操作意味着将Segment合并,并写入磁盘。保证内存数据尽量不丢。但刷盘是很重的IO操作,所以为了机器性能和近实时搜索,并不会刷盘那么及时。
Translog
新文档被索引意味着文档会被首先写入内存Buffer和Translog文件。每个Shard都对应一个Translog文件。
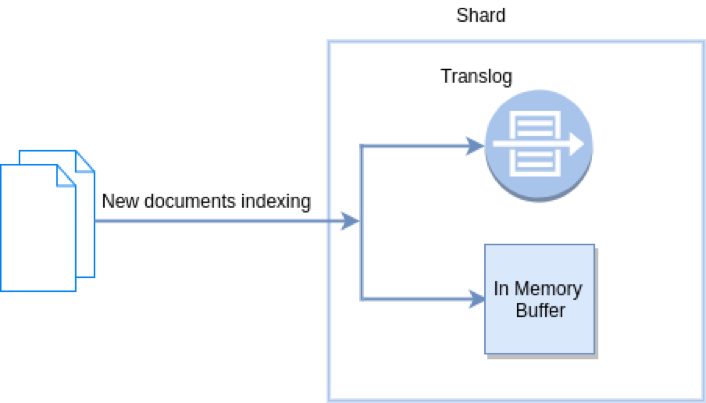
Refresh in Elasticsearch
在Elasticsearch中,refresh操作默认每秒执行一次, 意味着将内存Buffer的数据写入到一个新的Segment中,这个时候索引变成了可被检索的。写入新Segment后会清空内存Buffer。
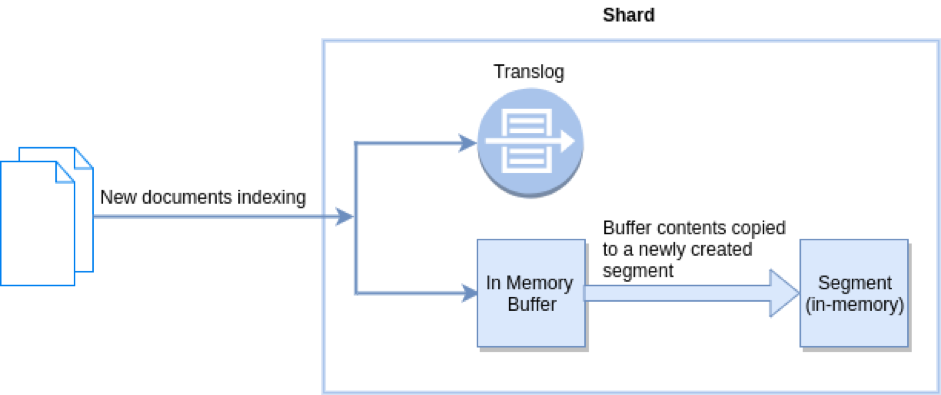
Flush in Elasticsearch
Flush操作意味着将内存Buffer的数据全都写入新的Segments中,并将内存中所有的Segments全部刷盘,并且清空 Translog日志的过程。
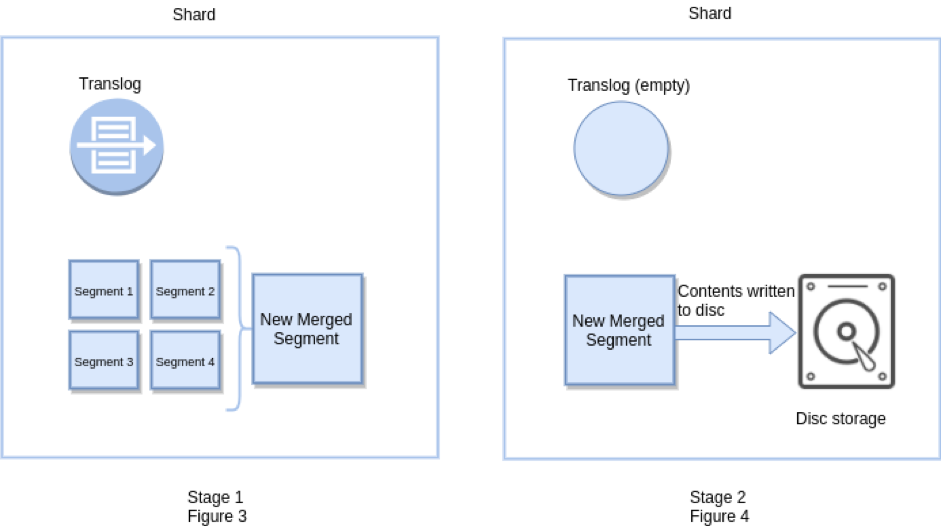
近实时搜索
提交(Commiting)一个新的段到磁盘需要一个fsync来确保段被物理性地写入磁盘,这样在断电的时候就不会丢失数据。 但是fsync操作代价很大,如果每次索引一个文档都去执行一次的话会造成很大的性能问题。
我们需要的是一个更轻量的方式来使一个文档可被搜索,这意味着fsync要从整个过程中被移除。
在 Elasticsearch和磁盘之间是文件系统缓存。 像之前描述的一样, 在内存索引缓冲区中的文档会被写入到一个新的段中。 但是这里新段会被先写入到文件系统缓存--这一步代价会比较低,稍后再被刷新到磁盘--这一步代价比较高。不过只要文件已经在系统缓存中, 就可以像其它文件一样被打开和读取了。
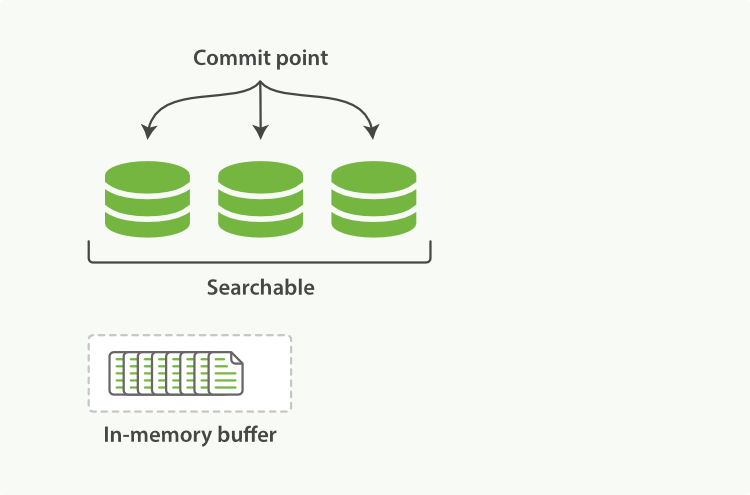
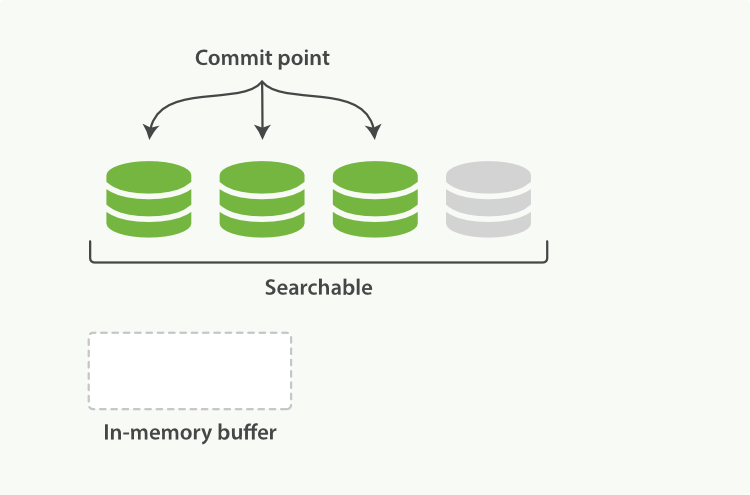
Lucene 允许新段被写入和打开--使其包含的文档在未进行一次完整提交时便对搜索可见。 这种方式比进行一次提交代价要小得多,并且在不影响性能的前提下可以被频繁地执行。
原理
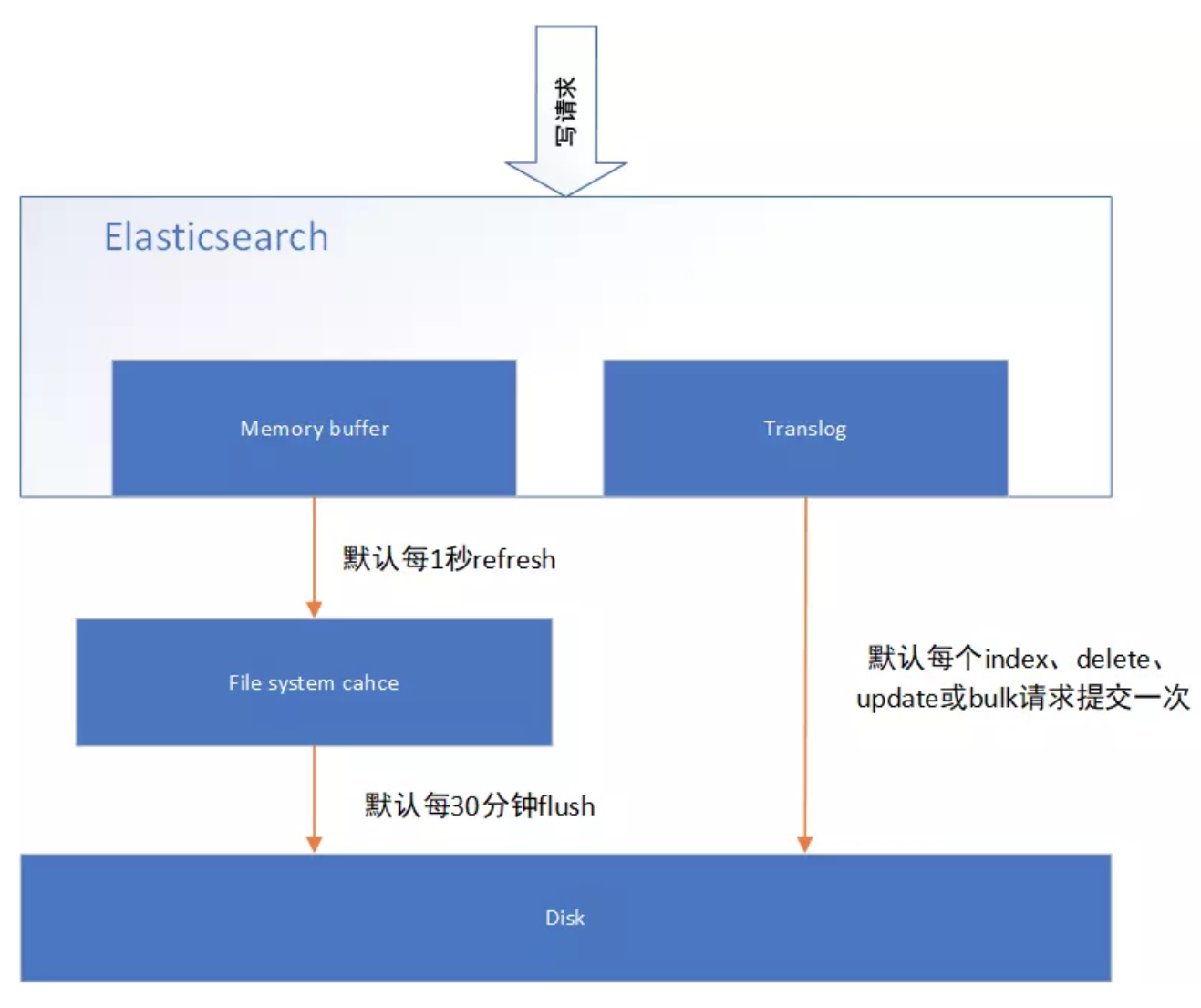
下图表示是ES写操作流程,当一个写请求发送到ES后,ES将数据写入Memory Buffer中,并添加事务日志( Translog )。如果每次一条数据写入内存后立即写到硬盘文件上,由于写入的数据肯定是离散的,因此写入硬盘的操作也就是随机写入了。硬盘随机写入的效率相当低,会严重降低ES的性能。因此ES在设计时在Memory Buffer和硬盘间加入了Linux 的高速缓存( File system cache )来提高ES的写效率。
当写请求发送到ES后,ES将数据暂时写入Memory Buffer中,此时写入的数据还不能被查询到。默认设置下,ES每1秒钟将Memory Buffer中的数据refresh到Linux的File system cache,并清空Memory Buffer,此时写入的数据就可以被查询到了。
refresh API
在Elasticsearch中,写入和打开一个新段的轻量的过程叫做refresh 。 默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说Elasticsearch是近实时搜索:文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
这些行为可能会对新用户造成困惑:他们索引了一个文档然后尝试搜索它,但却没有搜到。这个问题的解决办法是用refresh API执行一次手动刷新:
POST /_refresh
POST /my_blogs/_refresh
PUT /my_blogs/_doc/1?refresh
{"test": "test"}
PUT /test/_doc/2?refresh=true
{"test": "test"}并不是所有的情况都需要每秒刷新。可能你正在使用Elasticsearch索引大量的日志文件,你可能想优化索引速度而不是近实时搜索,可以通过设置refresh_interval, 降低每个索引的刷新频率。
PUT /my_logs
{
"settings": { "refresh_interval": "30s" }
}refresh_interval可以在既存索引上进行动态更新。在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,待开始使用该索引时,再把它们调回来:
PUT /my_logs/_settings
{ "refresh_interval": -1 }
PUT /my_logs/_settings
{ "refresh_interval": "1s" }持久化变更
原理
如果没有用fsync把数据从文件系统缓存刷(flush)到硬盘,我们不能保证数据在断电甚至是程序正常退出之后依然存在。为了保证Elasticsearch的可靠性,需要确保数据变化被持久化到磁盘。
在动态更新索引时,我们说一次完整的提交会将段刷到磁盘,并写入一个包含所有段列表的提交点。Elasticsearch 在启动或重新打开一个索引的过程中使用这个提交点来判断哪些段隶属于当前分片。
即使通过每秒刷新(refresh)实现了近实时搜索,我们仍然需要经常进行完整提交来确保能从失败中恢复。但在两次提交之间发生变化的文档怎么办?我们也不希望丢失掉这些数据。
Elasticsearch增加了一个Translog,或者叫事务日志,在每一次对Elasticsearch进行操作时均进行了日志记录。通过 Translog,整个流程看起来是下面这样:
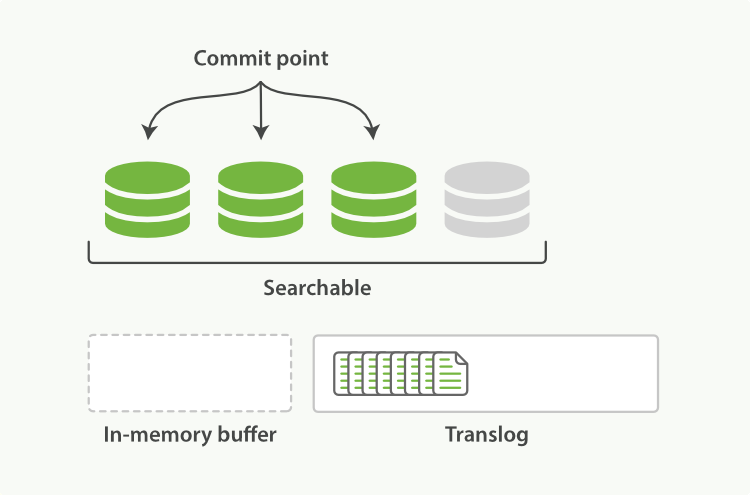
新的文档被添加到内存缓冲区并且被追加到了事务日志:
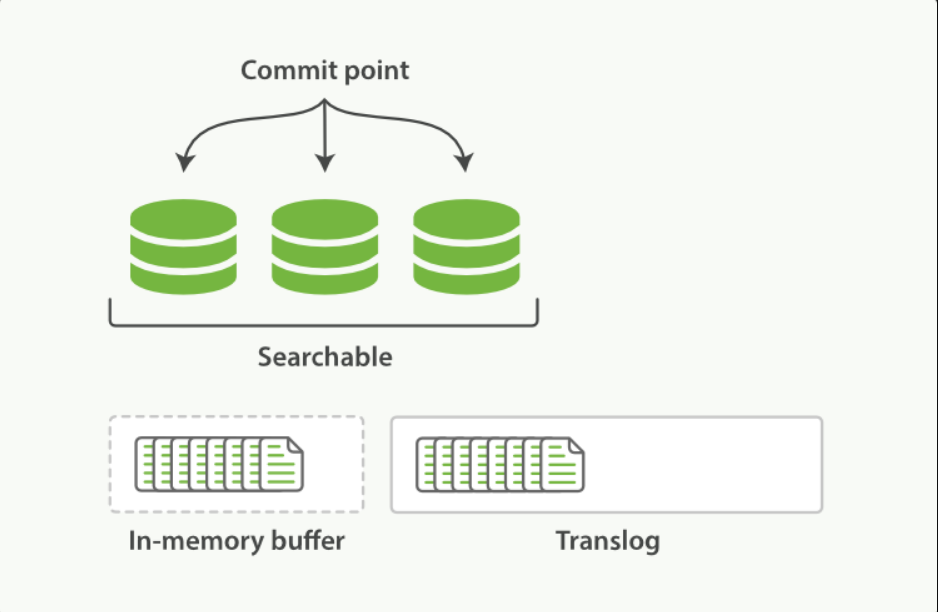
刷新(refresh)使分片处于下图描述的状态,分片每秒被刷新(refresh)一次:
- 这些在内存缓冲区的文档被写入到一个新的段中,且没有进行
fsync操作 - 这个段被打开,使其可被搜索
- 内存缓冲区被清空
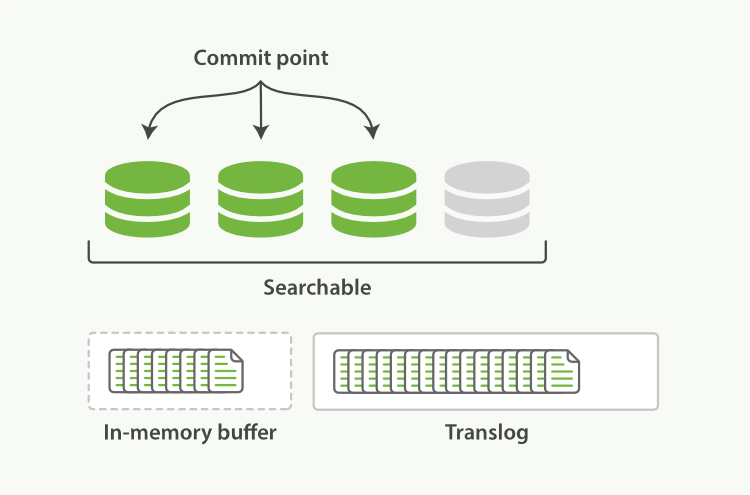
刷新(refresh)完成后, 缓存被清空但是事务日志不会:
事务日志不断积累文档:
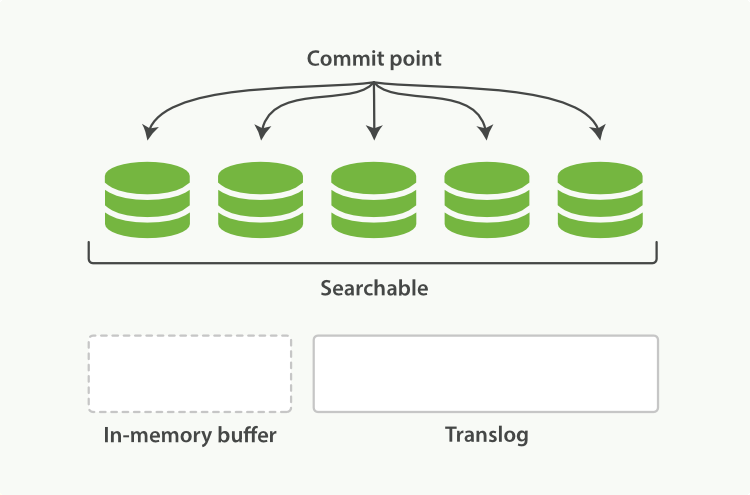
每隔一段时间--例如Translog变得越来越大--索引被刷新(flush),一个新的Translog被创建,并且一个全量提交被执行:
- 所有在内存缓冲区的文档都被写入一个新的段
- 缓冲区被清空
- 一个提交点被写入硬盘
- 文件系统缓存通过
fsync被刷新(flush) - 老的Translog被删除
Translog提供所有还没有被刷到磁盘的操作的一个持久化纪录。当Elasticsearch启动的时候, 它会从磁盘中使用最后一个提交点去恢复已知的段,并且会重放Translog中所有在最后一次提交后发生的变更操作。
Translog也被用来提供实时CRUD 。当你试着通过ID查询、更新、删除一个文档,它会在尝试从相应的段中检索之前, 首先检查Translog任何最近的变更。这意味着它总是能够实时地获取到文档的最新版本。
flush API
这个执行一个提交并且截断Translog的行为在Elasticsearch被称作一次flush 。 分片每30分钟被自动刷新(flush),或者在Translog太大的时候也会刷新。
flush API可以被用来执行一个手工的刷新(flush):
POST /blogs/_flush
POST /_flush?wait_for_ongoin- 刷新(flush)blogs索引
- 刷新(flush)所有的索引并且等待所有刷新在返回前完成
我们很少需要自己手动执行一个的flush操作,通常情况下,自动刷新就足够了。
这就是说,在重启节点或关闭索引之前执行flush有益于你的索引。当Elasticsearch尝试恢复或重新打开一个索引, 它需要重放Translog中所有的操作,所以如果日志越短,恢复越快。
Translog 有多安全?
在文件被fsync到磁盘前,被写入的文件在重启之后就会丢失。默认Translog是每5秒被fsync刷新到硬盘, 或者在每次写请求完成之后执行(e.g. index, delete, update, bulk)。这个过程在主分片和复制分片都会发生。最终, 基本上,这意味着在整个请求被fsync到主分片和复制分片的Translog之前,你的客户端不会得到一个200 OK响应。
在每次写请求后都执行一个fsync会带来一些性能损失,尽管实践表明这种损失相对较小(特别是bulk导入,它在一次请求中平摊了大量文档的开销)。
但是对于一些大容量的偶尔丢失几秒数据问题也并不严重的集群,使用异步的fsync还是比较有益的。比如,写入的数据被缓存到内存中,再每5秒执行一次fsync 。
这个行为可以通过设置durability参数为async来启用:
PUT /my_index/_settings {
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}这个选项可以针对索引单独设置,并且可以动态进行修改。如果你决定使用异步Translog的话,你需要保证在发生crash时,丢失掉sync_interval时间段的数据也无所谓。请在决定前知晓这个特性。
如果你不确定这个行为的后果,最好是使用默认的参数( "index.translog.durability":"request" )来避免数据丢失。
索引文档存储段合并机制
段合并机制
由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。 每一个段都会消耗文件句柄、内存和 CPU 运行周期。更重要的是,每个搜索请求都必须轮流检查每个段。所以段越多,搜索也就越慢。
Elasticsearch通过在后台进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。段合并的时候会将那些旧的已删除文档从文件系统中清除。 被删除的文档(或被更新文档的旧版本)不会被拷贝到新的大段中。
启动段合并在进行索引和搜索时会自动进行。这个流程像在下图中演示的一样工作:
- 当索引的时候,刷新(
refresh)操作会创建新的段并将段打开以供搜索使用 - 合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中。这并不会中断索引和搜索
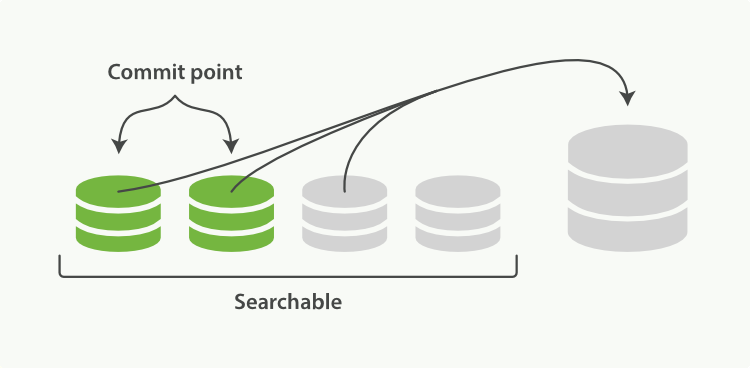
合并完成时的活动:
- 新的段被刷新(
flush)到了磁盘。写入一个包含新段且排除旧的和较小的段的新提交点 - 新的段被打开用来搜索
- 老的段被删除
合并大的段需要消耗大量的I/O和CPU资源,如果任其发展会影响搜索性能。Elasticsearch在默认情况下会对合并流程进行资源限制,所以搜索仍然有足够的资源很好地执行。默认情况下,归并线程的限速配置 indices.store.throttle.max_bytes_per_sec是20MB。对于写入量较大,磁盘转速较高,甚至使用SSD盘的服务器来说,这个限速是明显过低的。对于ELK Stack应用,建议可以适当调大到100MB或者更高。
PUT /_cluster/settings
{
"persistent" : {
"indices.store.throttle.max_bytes_per_sec" : "100mb"
}
}index.merge.scheduler.max_thread_count用于控制归并线程的数目,推荐设置为CPU核心数的一半。 如果觉得自己磁盘性能跟不上,可以降低配置,免得IO情况瓶颈。
归并策略
归并线程是按照一定的运行策略来挑选Segment进行归并的。主要有以下几条:
index.merge.policy.floor_segment:默认 2MB,小于这个大小的Segment,优先被归并index.merge.policy.max_merge_at_once:默认一次最多归并10个Segmentindex.merge.policy.max_merge_at_once_explicit:默认optimize时一次最多归并30个Segmentindex.merge.policy.max_merged_segment:默认5GB,大于这个大小的Segment,不用参与归并,optimize除外
optimize API
optimize API大可看做是强制合并API。它会将一个分片强制合并到max_num_segments参数指定大小的段数目。 这样做的意图是减少段的数量(通常减少到一个),来提升搜索性能。
在特定情况下,使用optimize API颇有益处。例如在日志这种用例下,每天、每周、每月的日志被存储在一个索引中。 老的索引实质上是只读的,它们也并不太可能会发生变化。在这种情况下,使用optimize优化老的索引,将每一个分片合并为一个单独的段就很有用了。这样既可以节省资源,也可以使搜索更加快速:
POST /logstash-2014-10/_optimize?max_num_segments=1forceMergeRequest.maxNumSegments(1)并发冲突处理机制剖析
详解并发冲突
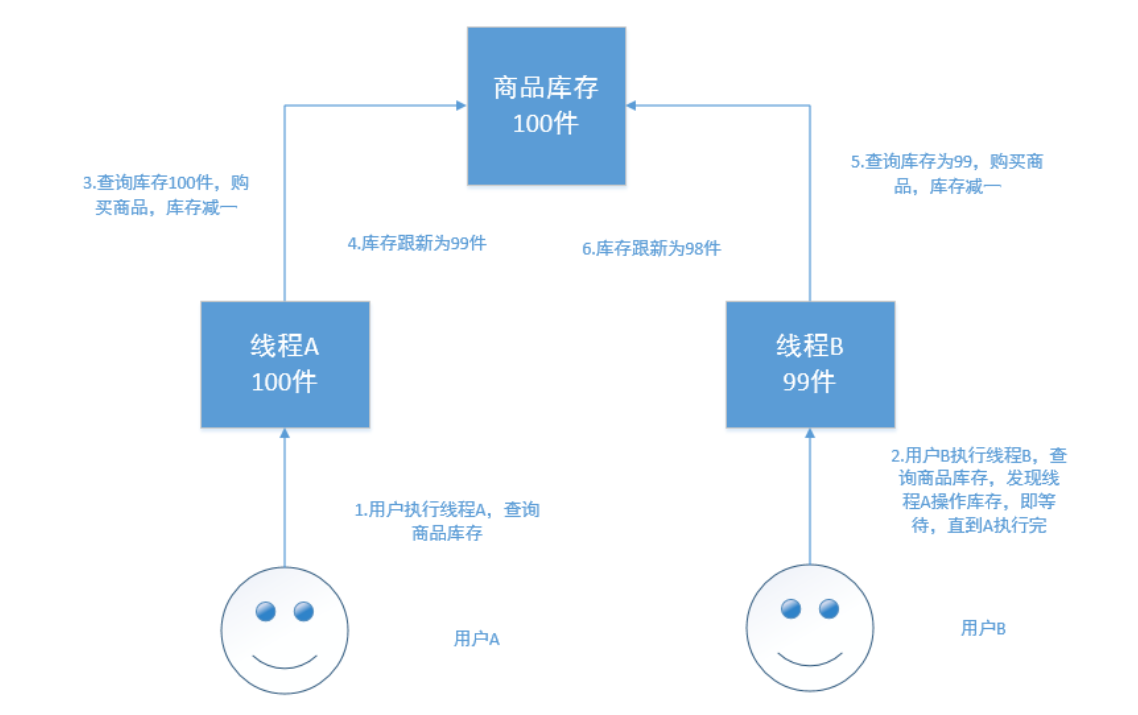
在电商场景下,工作流程为:
- 读取商品信息,包括库存数量
- 用户下单购买
- 更新商品信息,将库存数减一
如果是多线程操作,就可能有多个线程并发的去执行上述的3步骤流程,假如此时有两个人都来读取商品数据,两个线程并发的服务于两个人,同时在进行商品库存数据的修改。假设库存为100件 正确的情况:线程A将库存-1,设置为99件,线程B接着读取99件,再-1,变为98件。如果A、B线程都读取的为100件,A处理完之后修改为99件,B处理完之后再次修改为99件,此时结果就出错了。
解决方案
悲观锁
顾名思义,就是很悲观,每次去拿数据的时候都认为被人会修改,所以每次拿数据的时候都会加锁,以防别人修改,直到操作完成后,才会被别人执行。常见的关系型数据库,就用到了很多这样的机制,如行锁,表锁,写锁,都是在操作之前加锁。
悲观锁的优点:方便,直接加锁,对外透明,不需要额外的操作。
悲观锁的缺点:并发能力低,同一时间只能有一个操作。
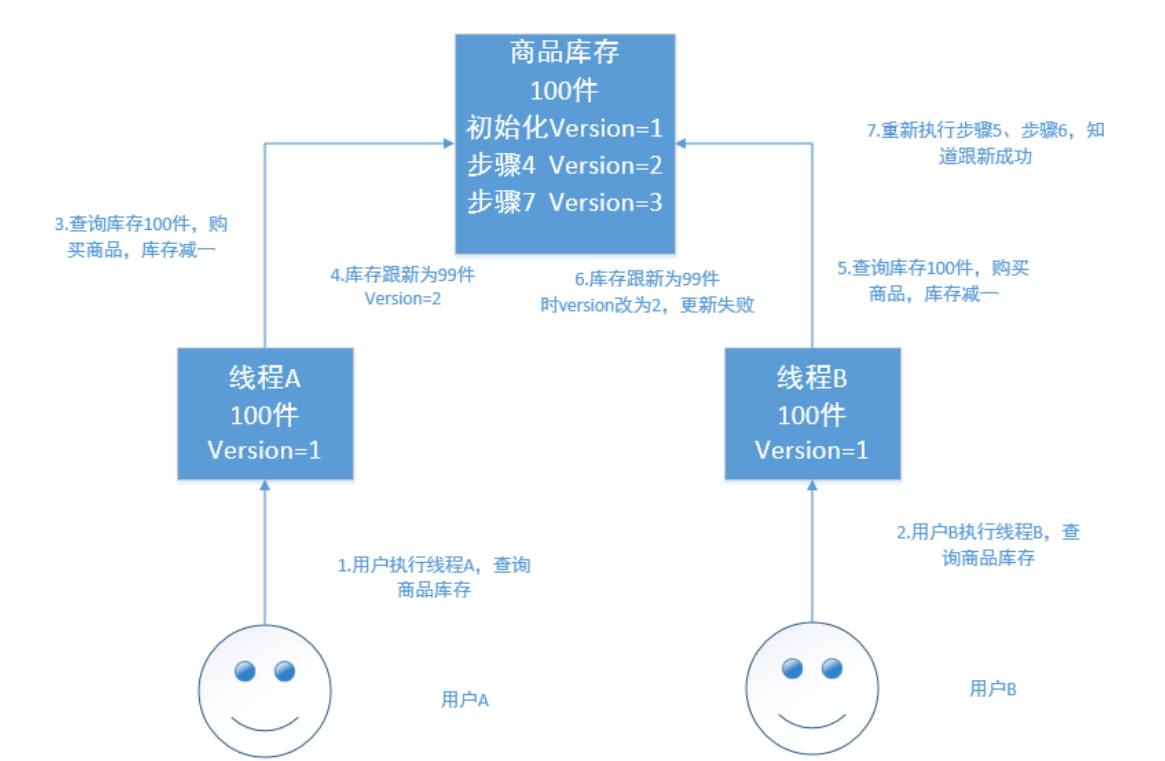
乐观锁
乐观锁不加锁,每个线程都可以任意操作。比如每条文档中有一个version字段,新建文档后为1,修改一次累加,线程A、B同时读取到数据,version=1,A处理完之后库存为99,在写入ES的时候会跟ES中的版本号比较,都是1,则写入成功,version=2,B处理完之后也为99,存入ES时与ES中的数据的版本号version=2相比,明显不同,此时不会用99去更新,而是重新读取最新的数据,再减一,变为98,执行上述操作写入。
Elasticsearch的乐观锁
Elasticsearch的后台都是多线程异步的,多个请求之间是乱序的,可能后修改的先到,先修改的后到。Elasticsearch的多线程异步并发修改是基于自己的_version版本号进行乐观锁并发控制的。
在后修改的先到时,比较版本号,版本号相同修改可以成功,而当先修改的后到时,也会比较一下_version版本号,如果不相等就再次读取新的数据修改。这样结果会就会保存为一个正确状态。
删除操作也会对这条数据的版本号加1。
在删除一个document之后,可以从一个侧面证明,它不是立即物理删除掉的,因为它的一些版本号等信息还是保留着的。先删除一条document,再重新创建这条document,其实会在delete version基础之上,再把version号加1。
Elasticsearch的乐观锁并发控制示例
- 先新建一条数据
UT /test_index/_doc/4
{
"test_field": "test"
}- 模拟两个客户端,都获取到了同一条数据
GET /test_index/_doc/4
返回
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "4",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"test_field" : "test"
}
}- 其中一个客户端,先更新了一下这个数据, 同时带上数据的版本号,确保说,ES中的数据的版本号,跟客户端中的数据的版本号(
_seq_no)是相同的,才能修改
PUT /test_index/_doc/4
{
"test_field": "client1 changed"
}
返回结果
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "4",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}- 另外一个客户端,尝试基于
version=1的数据去进行修改,同样带上(if_seq_no和if_primary_term)version版本号,进行乐观锁的并发控制
PUT /test_index/_doc/4?if_seq_no=0&if_primary_term=1
{
"test_field": "client2 changed"
}
会出错,返回
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[4]: version conflict, required seqNo [0], primary term
[1]. current document has seqNo [1] and primary term [1]",
"index_uuid": "RLebBAGvR9iWdUoi3t5bXw",
"shard": "0",
"index": "test_index"
}
],
"type": "version_conflict_engine_exception",
"reason": "[4]: version conflict, required seqNo [0], primary term [1].
current document has seqNo [1] and primary term [1]",
"index_uuid": "RLebBAGvR9iWdUoi3t5bXw",
"shard": "0",
"index": "test_index"
},
"status": 409
}乐观锁就成功阻止并发问题。
- 在乐观锁成功阻止并发问题之后,尝试正确的完成更新
重新进行GET请求,得到version:
GET /test_index/_doc/4
结果
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "4",
"_version" : 2,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"test_field" : "client1 changed"
}
}基于最新的数据和版本号(以前是version现在是if_seq_no和if_primary_term),去进行修改,修改后,带上最新的版本号,可能这个步骤会需要反复执行好几次,才能成功,特别是在多线程并发更新同一条数据很频繁的情况下。
PUT /test_index/_doc/4?if_seq_no=1&if_primary_term=1
{
"test_field": "client2 changed"
}
返回
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "4",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}基于external version进行乐观锁并发控制
ES提供了一个feature,就是说,你可以不用它提供的内部_version版本号来进行并发控制,可以基于你自己维护的一个版本号来进行并发控制。
?version=1&version_type=external区别在于,_version方式,只有当你提供的_version与ES中的_version一模一样的时候,才可以进行修改,只要不一样,就报错;当version_type=external的时候,只有当你提供的_version比ES中的_version大的时候,才能完成修改。
代码示例:
- 先创建一条数据
PUT /test_index/_doc/5
{
"test_field": "external test"
}- 模拟两个客户端同时查询到这条数据
GET /test_index/_doc/5- 第一个客户端先进行修改,此时客户端程序是在自己的数据库中获取到了这条数据的最新版本号,比如说是2
PUT /test_index/_doc/5?version=2&version_type=external
{
"test_field": "external client1 changed"
}- 模拟第二个客户端,同时拿到了自己数据库中维护的那个版本号,也是2,同时基于
version=2发起了修改
PUT /test_index/_doc/5?version=2&version_type=external
{
"test_field": "external client2 changed"
}- 在并发控制成功后,重新基于最新的版本号发起更新
GET /test_index/_doc/5
PUT /test_index/_doc/5?version=3&version_type=external
{
"test_field": "external client2 changed"
}分布式数据一致性如何保证
在分布式环境下,一致性指的是多个数据副本是否能保持一致的特性。
在一致性的条件下,系统在执行数据更新操作之后能够从一致性状态转移到另一个一致性状态。
对系统的一个数据更新成功之后,如果所有用户都能够读取到最新的值,该系统就被认为具有强一致性。
ES5.0以前的一致性
我们在发送任何一个增删改操作的时候,比如PUT /index/indextype/id,都可以带上一个consistency参数,指明我们想要的写一致性是什么?
比如:
PUT /index/indextype/id?consistency=quorumconsistency参数包括:
- one:要求我们这个写操作,只要有一个
primary shard是active状态,就可以执行 - all:要求我们这个写操作,必须所有的
primary shard和replica shard都是活跃的,才可以执行这个写操作 - quorum:默认值,要求所有的
shard中,必须是法定数的shard都是活跃的,可用的,才可以执行这个写操作
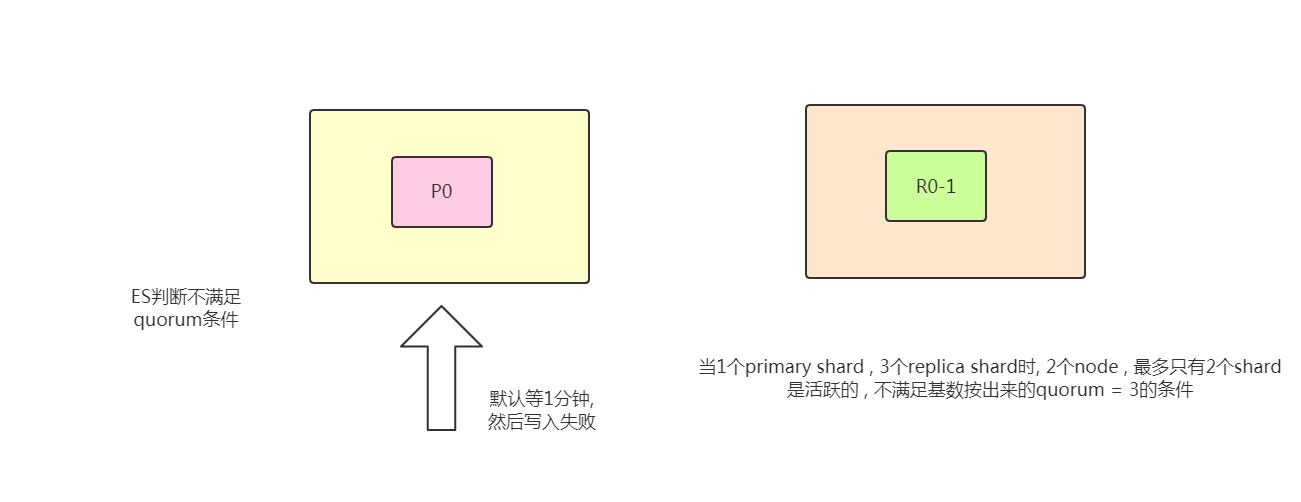
quorum机制
写之前必须确保法定数shard可用。公式如下:
int((primary shard + number_of_replicas) / 2) + 1
(当number_of_replicas > 1时才生效)
比如有1个primary shard,3个replica shard,那么quorum=((1 + 3) / 2) + 1 = 3,要求3个primary shard + 1个replica shard=4个shard中必须有3个shard是要处于active状态,若这时候只有两台机器的话,会出现什么情况?
timeout机制
quorum不齐全时,会wait(等待)1分钟。
默认1分钟,可以设置timeout手动去调,默认单位毫秒。
等待期间,期望活跃的shard数量可以增加,最后无法满足shard数量就会timeout,我们其实可以在写操作的时候,加一个timeout参数,比如说PUT /index/_doc/id?timeout=30s,这个就是说自己去设定quorum不齐全的时候,ES的timeout时长。默认是毫秒,加个s代表秒。
ElasticSearch5.0以及以后的版本
从ES5.0后,原先执行PUT带consistency=all/quorum参数的,都报错了,提示语法错误。
原因是consistency检查是在PUT之前做的。然而,虽然检查的时候,shard满足quorum,但是真正从primary shard写到replica shard之前,仍会出现shard挂掉,但UPDATE API会返回succeed。因此,这个检查并不能保证replica shard成功写入,甚至这个primary shard是否能成功写入也未必能保证。。
因此,修改了语法,用了下面的wait_for_active_shards,因为这个更能清楚表述,而没有歧义。
PUT /test_index/_doc/1?wait_for_active_shards=2&timeout=10s
{
"name":"xiao mi"
}Query文档搜索机制剖析
Elasticsearch的搜索类型(SearchType类型)
2.0之前有四种:QUERY_AND_FETCH、DFS_QUERY_AND_FETCH、QUERY_THEN_FETCH和DFS_QUERY_THEN_FETCH。
2.0版本之后,只有两种了:QUERY_THEN_FETCH和DFS_QUERY_THEN_FETCH。
可以通过java的API设置:
SearchRequest searchRequest = new SearchRequest(POSITION_INDEX);
searchRequest.setSearchType(SearchType.DFS_QUERY_THEN_FETCH)QUERY_AND_FETCH
向索引的所有分片( shard)都发出查询请求,各分片返回的时候把元素文档 ( document)和计算后的排名信息一起返回。
这种搜索方式是最快的。 因为相比下面的几种搜索方式, 这种查询方法只需要去shard查询一次。 但是各个shard 返回的结果的数量之和可能是用户要求的size的n倍。
优点:这种搜索方式是最快的。因为相比后面的几种ES的搜索方式,这种查询方法只需要去shard查询一次。
缺点:返回的数据量不准确, 可能返回(n * 分片数量)的数据并且数据排名也不准确,同时各个shard返回的结果的数量之和可能是用户要求的size的n倍。
DFS_QUERY_AND_FETCH
这个D是Distributed,F是Frequency的缩写,至于S是Scatter的缩写,整个DFS是分布式词频率和文档频率散发的缩写。DFS其实就是在进行真正的查询之前, 先把各个分片的词频率和文档频率收集一下, 然后进行词搜索的时候, 各分片依据全局的词频率和文档频率进行搜索和排名。这种方式比第一种方式多了一个DFS步骤(初始化散发(initial scatter)),可以更精确控制搜索打分和排名。也就是在进行查询之前,先对所有分片发送请求, 把所有分片中的词频和文档频率等打分依据全部汇总到一块,再执行后面的操作。
优点:数据排名准确。
缺点:性能一般,返回的数据量不准确,可能返回(n * 分片数量)的数据。
QUERY_THEN_FETCH(ES默认的搜索方式)
如果你搜索时,没有指定搜索方式,就是使用的这种搜索方式。这种搜索方式,大概分两个步骤:
- 第一步, 先向所有的
shard发出请求, 各分片只返回文档id(注意:不包括文档document)和排名相关的信息(也就是文档对应的分值),然后按照各分片返回的文档的分数进行重新排序和排名,取前size个文档 - 第二步,根据文档
id去相关的shard取document。 这种方式返回的document数量与用户要求的大小是相等的
详细过程:
- 发送查询到每个
shard - 找到所有匹配的文档,并使用本地的
Term/Document Frequency信息进行打分 - 对结果构建一个优先队列(排序,标页等)
- 返回关于结果的元数据到请求节点。注意,实际文档还没有发送,只是分数
- 来自所有
shard的分数合并起来,并在请求节点上进行排序,文档被按照查询要求进行选择 - 最终,实际文档从他们各自所在的独立的
shard上检索出来 - 结果被返回给用户
优点:返回的数据量是准确的。
缺点:性能一般,并且数据排名不准确。
DFS_QUERY_THEN_FETCH
比第3种方式多了一个DFS步骤。
也就是在进行查询之前, 先对所有分片发送请求, 把所有分片中的词频和文档频率等打分依据全部汇总到一块, 再执行后面的操作。
详细步骤:
- 预查询每个
shard,询问Term和Document frequency - 发送查询到每个
shard - 找到所有匹配的文档,并使用全局的
Term/Document Frequency信息进行打分 - 对结果构建一个优先队列(排序,标页等)
- 返回关于结果的元数据到请求节点。注意,实际文档还没有发送,只是分数
- 来自所有
shard的分数合并起来,并在请求节点上进行排序,文档被按照查询要求进行选择 - 最终,实际文档从他们各自所在的独立的shard上检索出来
- 结果被返回给用户
优点:返回的数据量是准确的,数据排名准确。
缺点:性能最差( 这个最差只是表示在这四种查询方式中性能最慢, 也不至于不能忍受,如果对查询性能要求不是非常高, 而对查询准确度要求比较高的时候可以考虑这个)。
文档增删改和搜索请求过程
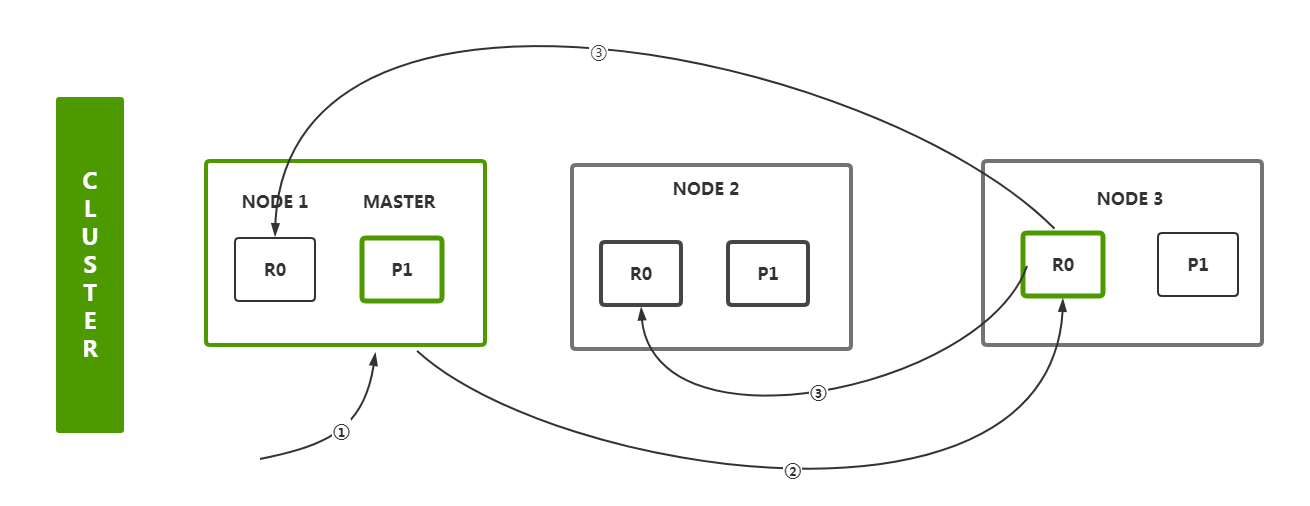
增删改流程
- 客户端首先会选择一个节点
node发送请求过去,这个节点node可能是协调节点coordinating node - 协调节点
coordinating node会对document数据进行路由,将请求转发给对应的node(含有primary shard) - 实际上
node的primary shard会处理请求,然后将数据同步到对应的含有replica shard的node - 协调节点
coordinating node如果发现含有primary shard的node和所有的含有replica shard的node符合要求的数量之后,就会返回响应结果给客户端
search流程
- 客户端首先会选择一个节点
node发送请求过去,这个节点node可能是协调节点coordinating node - 协调节点将搜索请求转发到所有的
shard对应的primary shard或replica shard,都可以 query phase:每个shard将自己的搜索结果的元数据到请求节点(其实就是一些doc id和打分信息等返回给协调节点),由协调节点进行数据的合并、排序、分页等操作,产出最终结果fetch phase:接着由协调节点根据doc id去各个节点上拉取实际的document数据,最终返回给客户端
相关性评分算法BM25
BM25算法
BM25(Best Match25)是在信息检索系统中根据提出的query对document进行评分的算法。
TF-IDF算法是一个可用的算法,但并不太完美。而BM25算法则是在此之上做出改进之后的算法。
- 当两篇描述“人工智能”的文档A和B,其中A出现“人工智能”100次,B出现“人工智能”200次。两篇文章的单词数量都是10000,那么按照
TF-IDF算法,A的TF得分是:0.01,B的TF得分是0.02。得分上B比A多了一倍,但是两篇文章都是再说人工智能,TF分数不应该相差这么多。可见单纯统计的TF算法在文本内容多的时候是不可靠的 - 多篇文档内容的长度长短不同,对
TF算法的结果也影响很大,所以需要将文本的平均长度也考虑到算法当中去
基于上面两点,BM25算法做出了改进:
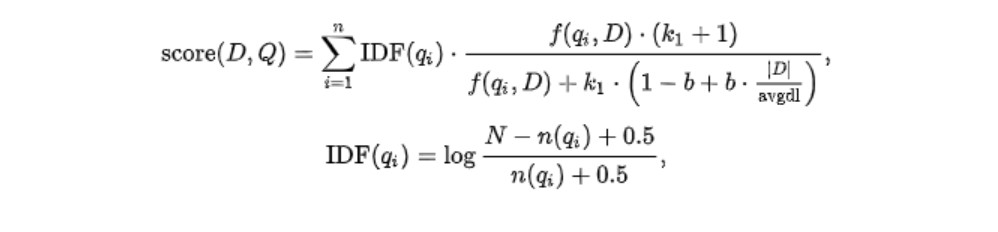
- k1:词语频率饱和度(term frequency saturation)。它用于调节饱和度变化的速率。它的值一般介于1.2到2.0之间。数值越低则饱和的过程越快速。(意味着两个上面A、B两个文档有相同的分数,因为他们都包含大量的“人工智能”这个词语都达到饱和程度)。在ES应用中为1.2
- b:字段长度归约。将文档的长度归约化到全部文档的平均长度,它的值在0和1之间,1意味着全部归约化,0则不进行归约化。在ES的应用中为0.75
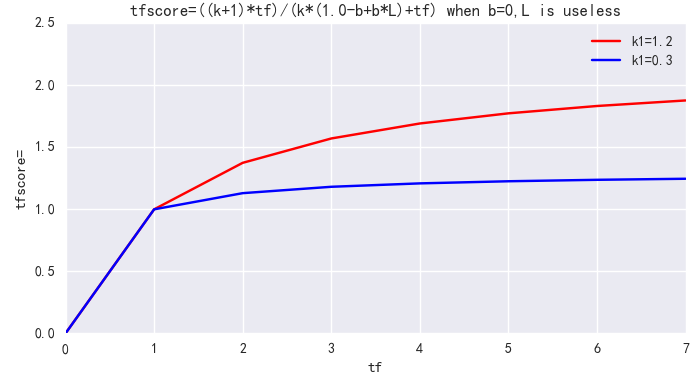
k1用来控制公式对词项频率TF的敏感程度。((k1 + 1) * TF) / (k1 + TF) 的上限是 (k1+1),也即饱和值。当k1=0 时,不管TF如何变化,BM25后一项都是1。随着k1不断增大,虽然上限值依然是 (k1+1),但到达饱和的TF值也会越大。当k1 无限大时,BM25后一项就是原始的词项频率。一句话,k1就是衡量高频Term所在文档和低频Term所在文档的相关性差异,在我们的场景下,Term频次并不重要,该值可以设小。ES 中默认k1=1.2,可调整为 k1=0.3。
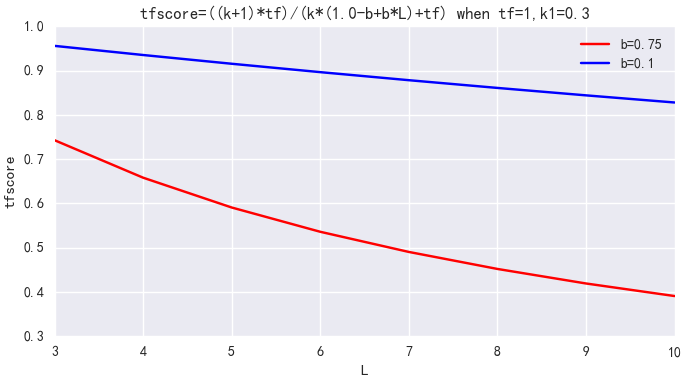
b是单个文档长度对相关性的影响力与它和平均长度的比值有关系,用来控制文档长度L对权值的惩罚程度。b=0,则文档长度对权值无影响,b=1,则文档长度对权值达到完全的惩罚作用。ES中默认b=0.75,可调整为 b=0.1。
ES中调整BM25
DELETE /my_index
PUT /my_index
{
"settings": {
"similarity": {
"my_bm25": {
"type": "BM25",
"b": 0.1,
"k1": 0.3
}
}
},
"mappings": {
"doc": {
"properties": {
"title": {
"type": "text",
"similarity": "my_bm25"
}
}
}
}
}
ES7
PUT /my_index
{
"settings": {
"similarity": {
"my_bm25": {
"type": "BM25",
"b": 0.1,
"k1": 0.3
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"similarity": "my_bm25"
}
}
}
}
GET /my_index排序那点事之内核级DocValues机制大揭秘
为什么要有Doc Values
我们都知道ElasticSearch之所以搜索这么快速,归功于他的倒排索引的设计,然而它也不是万能的,倒排索引的检索性能是非常快的,但是在字段值排序时却不是理想的结构。下面是一个简单的倒排索引的结构如下:
Term Doc_1 Doc_2
-------------------------
quick | | X
the | X |
brown | X | X
dog | X |
dogs | | X
fox | X |
foxes | | X
in | | X
jumped | X |
lazy | X | X
leap | | X
over | X | X
summer | | X
the | X |
------------------------如上表便可以看出,他只有词对应的Doc ,但是并不知道每一个Doc中的内容,那么如果想要排序的话每一个Doc都去获取一次文档内容岂不非常耗时? DocValues的出现使得这个问题迎刃而解。
字段的doc_values属性有两个值: true、false。默认为true,即开启。
当doc_values为fasle时,无法基于该字段排序、聚合、在脚本中访问字段值。
当doc_values为true时,ES会增加一个相应的正排索引,这增加的磁盘占用,也会导致索引数据速度慢一些。
Doc Values是什么
Doc Values通过转置倒排索引和正排索引两者间的关系来解决这个问题。倒排索引将词项映射到包含它们的文档, Doc Values将文档映射到它们包含的词项:
Doc Terms
-----------------------------------------------------------------
Doc_1 | brown, dog, fox, jumped, lazy, over, quick, the
Doc_2 | brown, dogs, foxes, in, lazy, leap, over, quick, summer
Doc_3 | dog, dogs, fox, jumped, over, quick, the
-----------------------------------------------------------------当数据被转置之后,想要收集到每个文档行,获取所有的词项就非常简单了。所以搜索使用倒排索引查找文档,聚合操作收集和聚合Doc Values里的数据,这就是ElasticSearch。
深入理解ElasticSearch Doc Values
Doc Values是在索引时与倒排索引同时生成。也就是说Doc Values和倒排索引 一样,基于Segement 生成并且是不可变的。同时Doc Values和倒排索引 一样序列化到磁盘,这样对性能和扩展性有很大帮助。
Doc Values 通过序列化把数据结构持久化到磁盘,我们可以充分利用操作系统的内存,而不是JVM的Heap 。 当 workingset远小于系统的可用内存,系统会自动将Doc Values保存在内存中,使得其读写十分高速。不过,当其远大于可用内存时,操作系统会自动把DocValues写入磁盘。很显然,这样性能会比在内存中差很多,但是它的大小就不再局限于服务器的内存了。如果是使用JVM的Heap来实现是因为容易OutOfMemory导致程序崩溃了。
Doc Values压缩
从广义来说, Doc Values本质上是一个序列化的列式存储,这个结构非常适用于聚合、排序、脚本等操作。而且,这种存储方式也非常便于压缩,特别是数字类型。这样可以减少磁盘空间并且提高访问速度。下面来看一组数字类型的 Doc Values :
Doc Terms
-----------------------------------------------------------------
Doc_1 | 100
Doc_2 | 1000
Doc_3 | 1500
Doc_4 | 1200
Doc_5 | 300
Doc_6 | 1900
Doc_7 | 4200
-----------------------------------------------------------------你会注意到这里每个数字都是100的倍数, Doc Values会检测一个段里面的所有数值,并使用一个最大公约数 ,方便做进一步的数据压缩。我们可以对每个数字都除以100,然后得到:[1,10,15,12,3,19,42] 。现在这些数字变小了,只需要很少的位就可以存储下,也减少了磁盘存放的大小。
Doc Values在压缩过程中使用如下技巧。它会按依次检测以下压缩模式:
- 如果所有的数值各不相同(或缺失),设置一个标记并记录这些值
- 如果这些值小于 256,将使用一个简单的编码表
- 如果这些值大于 256,检测是否存在一个最大公约数
- 如果没有存在最大公约数,从最小的数值开始,统一计算偏移量进行编码
当然如果存储String类型,其一样可以通过顺序表对String类型进行数字编码,然后再把数字类型构建Doc Values 。
禁用Doc Values
Doc Values默认对所有字段启用,除了analyzed strings。也就是说所有的数字、地理坐标、日期、IP 和不分析(not_analyzed)字符类型都会默认开启。
analyzed strings暂时还不能使用Doc Values,是因为经过分析以后的文本会生成大量的Token ,这样非常影响性能。
虽然Doc Values非常好用,但是如果你存储的数据确实不需要这个特性,就不如禁用它,这样不仅节省磁盘空间,也许会提升索引的速度。
要禁用Doc Values,在字段的映射(mapping)设置doc_values:false即可。例如,这里我们创建了一个新的索引,字段"session_id"禁用了Doc Values:
DELETE /my_index
PUT my_index
{
"mappings": {
"properties": {
"session_id": {
"type": "keyword",
"doc_values": false
}
}
}
}通过设置doc_values:false,这个字段将不能被用于聚合、排序以及脚本操作。
Filter过滤机制剖析(bitset机制与caching机制)
在倒排索引中查找搜索串,获取document list
解析:
date举例:倒排索引列表,过滤date为2020-02-02(filter:2020-02-02)。
去倒排索引中查找,发现2020-02-02对应的document list是doc2、doc3。
| word | doc1 | doc2 | doc3 |
| 2020-01-01 | * | * | |
| 2020-02-02 | * | * | |
| 2020-03-03 | * | * | * |
Filter为每个在倒排索引中搜索到的结果
解析:
- 使用找到的document list,构建一个bitset(二进制数组,用来表示一个document对应一个filter条件是否匹配,匹配为1,不匹配为0)
- 为什么使用bitset:尽可能用简单的数据结构去实现复杂的功能,可以节省内存空间、提升性能
- 由上步的document list可以得出该filter条件对应的bitset为:[0, 1, 1],代表着doc1不匹配filter,doc2、doc3匹配filter
多个过滤条件时,遍历每个过滤条件对应的bitset
解析:
- 多个filter组合查询时,每个filter条件都会对应一个bitset
- 稀疏、密集的判断是通过匹配的多少(即bitset中元素为1的个数)[0, 0, 0, 1, 0, 0] 比较稀疏,[0,1, 0, 1, 0, 1] 比较密集
- 先过滤稀疏的bitset,就可以先过滤掉尽可能多的数据
- 遍历所有的bitset、找到匹配所有filter条件的doc
- 将得到的document作为结果返回给client
caching bitset
解析:
- 比如postDate=2020-01-01:[0, 0, 1, 1, 0, 0]。可以缓存在内存中,这样下次如果再有该条件查询时,就不用重新扫描倒排索引,反复生成bitset,可以大幅提升性能
- 在最近256个filter中,有某个filter超过一定次数,次数不固定,就会自动缓存该filter对应的bitset
- filter针对小Segment获取的结果,可以不缓存,Segment记录数<1000,或者Segment大小 < Index总大小的3%(Segment数据量很小,此时哪怕是扫描也很快。Segment会在后台自动合并,小Segment很快就会跟其他小Segment合并成大Segment,此时缓存没有多大意义,因为Segment很快就会消失)
- filter比query的好处就在于有caching机制,filter bitset缓存起来便于下次不用扫描倒排索引。以后只要是由相同的filter条件的,会直接使用该过滤条件对应的cached bitset。比如postDate=2020-01-01:[0, 0, 1, 1, 0, 0],可以缓存在内存中,这样下次如果再有该条件查询时,就不用重新扫描倒排索引,反复生成bitset,可以大幅提升性能
如果document有新增或修改,那么cached bitset会被自动更新
示例:
- 新增document,id=5,postDate=2020-01-01。会自动更新到postDate=2020-01-01这个filter的bitset中,缓存要会进行相应的更新。postDate=2020-01-01的bitset:[0, 0, 1, 0, 1]
- 修改document,id=1,postDate=2019-01-31,修改为postDate=2020-01-01,此时也会自动更新bitset:[1, 0, 1, 0, 1]
filter大部分情况下,在query之前执行,先尽量过滤尽可能多的数据
- query:要计算doc对搜索条件的relevance score,还会根据这个score排序
- filter:只是简单过滤出想要的数据,不计算relevance score,也不排序
控制搜索精准度 - 基于boost的细粒度搜索的条件权重控制
boost,搜索条件权重。可以将某个搜索条件的权重加大,此时匹配这个搜索条件的document,在计算relevance score时,权重更大的搜索条件的document对应的relevance score会更高,当然也就会优先被返回回来。默认情况下,搜索条件的权重都是1。
示例:
DELETE /article
POST /article/_bulk
{ "create": { "_id": "1"} }
{"title" : "elasticsearch" }
{ "create": { "_id": "2"} }
{"title" : "java"}
{ "create": { "_id": "3"} }
{"title" : "elasticsearch"}
{ "create": { "_id": "4"} }
{"title" : "hadoop"}
{ "create": { "_id": "5"} }
{"title" : "spark"}
GET /article/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"title": {
"value": "java"
}
}
},
{
"term": {
"title": {
"value": "spark"
}
}
},
{
"term": {
"title": {
"value": "hadoop"
}
}
},
{
"term": {
"title": {
"value": "elasticsearch"
}
}
}
]
}
}
}搜索帖子,如果标题包含Hadoop或java或spark或Elasticsearch,就优先输出包含java的,再输出spark的,再输出Hadoop的,最后输出Elasticsearch的。
GET /article/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"title": {
"value": "java",
"boost": 5
}
}
},
{
"term": {
"title": {
"value": "spark",
"boost": 4
}
}
},
{
"term": {
"title": {
"value": "hadoop",
"boost": 3
}
}
},
{
"term": {
"title": {
"value": "elasticsearch"
}
}
}
]
}
}
}控制搜索精准度 - 基于dis_max实现best fields策略
为帖子数据增加content字段
POST /article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"content" : "i like to write best elasticsearch article"} }
{ "update": { "_id": "2"} }
{ "doc" : {"content" : "i think java is the best programming language"} }
{ "update": { "_id": "3"} }
{ "doc" : {"content" : "i am only an elasticsearch beginner"} }
{ "update": { "_id": "4"} }
{ "doc" : {"content" : "elasticsearch and hadoop are all very good solution, i
am a beginner"} }
{ "update": { "_id": "5"} }
{ "doc" : {"content" : "spark is best big data solution based on scala ,an
programming language similar to java"} }搜索title或content中包含java或solution的帖子
下面这个就是multi-field搜索,多字段搜索:
GET /article/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "java solution" }},
{ "match": { "content": "java solution" }}
]
}
}
}结果分析
期望的是doc5排在了前面,结果是doc2排在了前面。
算一下doc2的分数:
{ “match”: { “title”: “java solution” }},针对doc2,是有一个分数的。
{ “match”: { “content”: “java solution” }},针对doc2,也是有一个分数的。
所以是两个分数加起来,比如说,1.0 + 1.3 = 2.3。
算一下doc5的分数:
{ “match”: { “title”: “java solution” }},针对doc5,是没有分数的。
{ “match”: { “content”: “java solution” }},针对doc5,是有一个分数的。
所以说,只有一个query是有分数的,比如1.4。
best fields策略,dis_max
如果不是简单将每个字段的评分结果加在一起,而是将最佳匹配字段的评分作为查询的整体评分,结果会怎样?这样返回的结果可能是: 同时包含java和solution的单个字段比反复出现相同词语的多个不同字段有更高的相关度。
- best fields策略:就是说,搜索到的结果,应该是某一个field中匹配到了尽可能多的关键词,被排在前面,而不是尽可能多的field匹配到了少数的关键词,排在了前面
- dis_max语法:直接取多个query中,分数最高的那一个query的分数即可
{ “match”: { “title”: “java solution” }},针对doc2,是有一个分数的,1.0。
{ “match”: { “content”: “java solution” }},针对doc2,也是有一个分数的,1.3。
取最大分数,1.3。
{ “match”: { “title”: “java solution” }},针对doc5,是没有分数的。
{ “match”: { “content”: “java solution” }},针对doc5,是有一个分数的,1.4。
取最大分数,1.4。
然后doc2的分数 = 1.3 < doc5的分数 = 1.4,所以doc5就可以排在更前面的地方,符合我们的需要:
GET /article/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "java solution" }},
{ "match": { "content": "java solution" }}
]
}
}
}控制搜索精准度 - 基于function_score自定义相关度分数算法
Function score查询
在使用ES进行全文搜索时,搜索结果默认会以文档的相关度进行排序,而这个 "文档的相关度",是可以通过 function_score自己定义的,也就是说我们可以通过使用function_score,来控制 "怎样的文档相关度得分更高" 这件事。
function_score举例:
GET /book/_search
{
"query": {
"function_score": {
"query": { "match_all": {} },
"boost": "5",
"random_score": {}
}
}
}比如对book进行随机打分,如果没有给函数提供过滤,则等效于指定 "match_all":{}。
要排除不符合特定分数阈值的文档,可以将min_score参数设置为所需分数阈值。
function_score查询提供了几种类型的得分函数:
- script_score
- weight
- random_score
- field_value_factor
- decay functions: gauss, linear, exp
Field Value factor
field_value_factor函数可以使用文档中的字段来影响得分。与使用script_score函数类似,但是它避免了脚本编写的开销。如果用于多值字段,则在计算中仅使用该字段的第一个值。
举例:
GET /book/_search
{
"query": {
"match_all":{}
}
}
GET /book/_search
{
"query": {
"function_score": {
"field_value_factor": {
"field": "price",
"factor": 1.2,
"modifier": "sqrt"
}
}
}
}它将转化为以下得分公式:
sqrt(1.2 * doc['price'].value)field_value_factor函数有许多选项:
| 属性 | 说明 |
| field | 要从文档中提取的字段 |
| factor | 字段值乘以的值,默认为1 |
| modifier | 应用于字段值的修饰符可以是以下之一: none , log , log1p , log2p , ln , ln1p ,ln2p , square , sqrt , or reciprocal 。默认为无 |
modifier的取值:
| Modifier | 说明 |
| none | 不要对字段值应用任何乘数 |
| log | 取字段值的常用对数。因为此函数将返回负值并在0到1之间的值上使用时导致错误,所以建议改用log1p |
| log1p | 将字段值上加1并取对数 |
| log2p | 将字段值上加2并取对数 |
| ln | 取字段值的自然对数。因为此函数将返回负值并在0到1之间的值上使用时引起错误,所以建议改用 ln1p |
| ln1p | 将1加到字段值上并取自然对数 |
| ln2p | 将2加到字段值上并取自然对数 |
| square | 对字段值求平方(乘以它本身) |
| sqrt | 取字段值的平方根 |
| reciprocal | 交换字段值,与1/x相同,其中x是字段的值 |
field_value_score函数产生的分数必须为非负数,否则将引发错误。如果在0到1之间的值上使用log和ln修饰符将产生负值。请确保使用范围过滤器限制该字段的值以避免这种情况,或者使用log1p和ln1p。
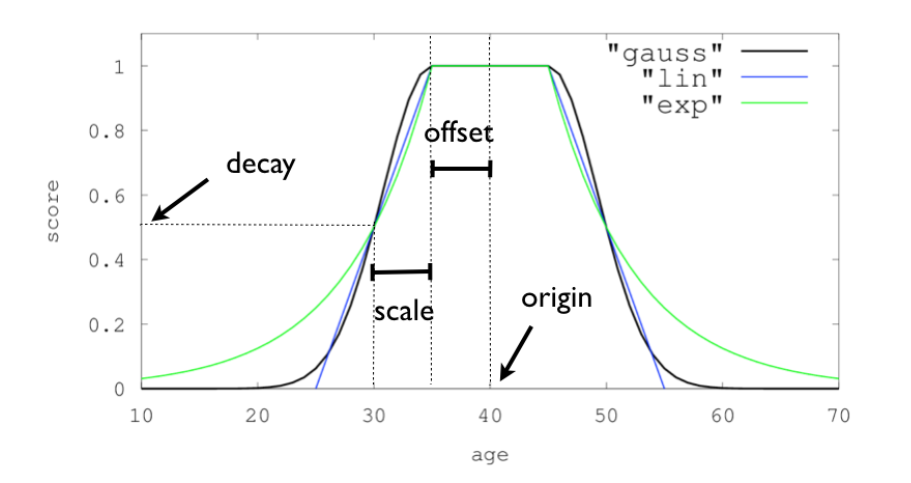
Decay functions
衰减函数对文档进行评分,该函数的衰减取决于文档的数字字段值与用户给定原点的距离。这类似于范围查询,但具有平滑的边缘而不是框。
要在具有数字字段的查询上使用距离计分,用户必须为每个字段定义origin和scale。需要origin来定义从中间计算距离的“中心点”,并需要scale来定义衰减率。衰减函数指定为:
"DECAY_FUNCTION": {
"FIELD_NAME": {
"origin": "11, 12",
"scale": "2km",
"offset": "0km",
"decay": 0.33
}
}DECAY_FUNCTION必须是linear、exp和gauss其中一个。
指定的字段必须是数字,日期或地理点字段。
在上面的例子中,该字段是geo_point,可以以地理格式提供起点。在这种情况下,必须使用scale和offset 。如果您的字段是日期字段,则可以将比例和偏移量设置为天,周等。如下:
GET /_search
{
"query": {
"function_score": {
"gauss": {
"date": {
"origin": "2013-09-17",
"scale": "10d",
"offset": "5d",
"decay" : 0.5
}
}
}
}
}原点的日期格式取决于映射中定义的格式。如果未定义原点,则使用当前时间。
offset和decay参数是可选的。
属性具体定义如下:
| 属性 | 说明 |
| origin | 用于计算距离的原点。对于数字字段,必须指定为数字;对于日期字段,必须指定为日期;对于地理字段,必须指定为地理点。地理位置和数字字段必填。对于日期字段,默认值为现在。原始日期支持日期数学(例如now-1h) |
| scale | 所有类型都必需。定义到原点的距离+偏移,计算出的分数将等于衰减参数。对于地理字段:可以定义为数字+单位(1m,12km,…)。默认单位是米。对于日期字段:可以定义为数字+单位(“ 1h”,“ 10d”,…。)。默认单位是毫秒。对于数字字段:任何数字 |
| offset | 如果定义了偏移量,则衰减函数将仅计算距离大于定义的偏移量的文档的衰减函数。默认值为0 |
| decay | 衰减参数定义了如何按比例给定的距离对文档进行评分。如果未定义衰减,则距离尺度的文档将获得0.5分 |
在第一个示例中,您的文档可能代表酒店,并且包含地理位置字段。您要根据酒店距指定位置的距离来计算衰减函数。 您可能不会立即看到为高斯功能选择哪种比例,但是您可以说:“在距所需位置2公里的距离处,分数应降低到0.33。” 然后将自动调整参数“规模”,以确保得分功能为距离期望位置2公里的酒店计算出高于0.33的得分。
在第二个示例中,字段值在2013-09-12和2013-09-22之间的文档的权重为1.0,从该日期起15天的文档的权重为0.5。
支持的衰减函数
gauss
正常衰减,计算如下:
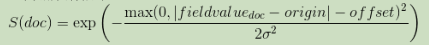
σ 计算以确保分数采用距原点+偏移量的距离尺度上的值衰减:
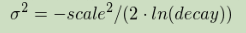
exp
指数衰减,计算如下:
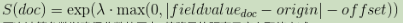
再次计算参数以确保分数从原点+偏移量的距离尺度上取值衰减:
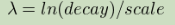
linear
线性衰减,计算如下:
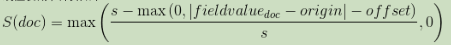
再次计算参数s以确保分数从原点+偏移量开始在距离标度上取值衰减:
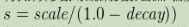
与正常和指数衰减相反,如果字段值超过用户给定标度值的两倍,则此功能实际上将分数设置为0。
对于单个函数,三个衰减函数及其参数可以像这样可视化(在此示例中,该字段称为“年龄”):
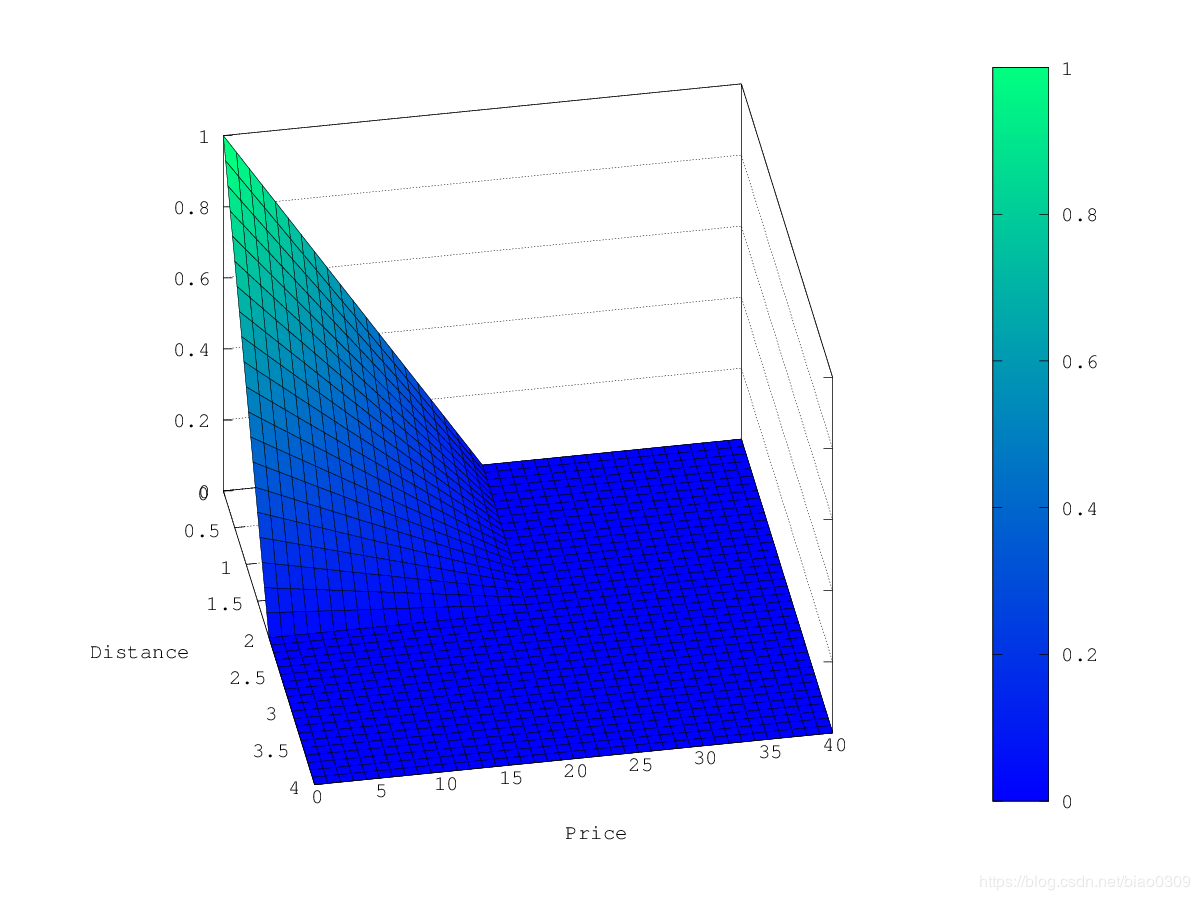
详细例子
假设您正在寻找某个城镇的酒店。您的预算有限。另外,您希望酒店离市中心很近,因此酒店距离理想位置越远,您入住的可能性就越小。
您希望根据距市中心的距离以及价格来对与您的条件相匹配的查询结果(例如“酒店,南希,不吸烟者”)进行评分。
直观地讲,您想将市中心定义为起点,也许您愿意从酒店步行2公里到市中心。在这种情况下,您的位置字段的来源为镇中心,范围为0〜2km。
如果您的预算低,您可能更喜欢便宜的东西而不是昂贵的东西。对于价格字段,原点为0欧元,小数位数取决于您愿意支付的金额,例如20欧元。
酒店的数据:
DELETE /hotel
PUT /hotel
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"price": {
"type": "float"
},
"location": {
"type": "geo_point"
}
}
}
}
PUT /hotel/_doc/1
{
"name": "Backback Nap",
"price": 18,
"location": "0,0.0002"
}
PUT /hotel/_doc/2
{
"name": "Hilton",
"price": 180,
"location": "0,0.0001"
}
PUT /hotel/_doc/3
{
"name": "Drink n Drive",
"price": 13,
"location": "0,0.018"
}
PUT /hotel/_doc/4
{
"name": "BnB Bellevue",
"price": 10,
"location": "0,0.0005"
}
PUT /hotel/_doc/5
{
"name": "Abu Dhabi",
"price": 1800,
"location": "0,0.20"
}
在此示例中,字段可能被称为“价格”作为酒店价格,而“位置”则称为该酒店的坐标。
在这种情况下,价格字段定义为:
# 此衰减函数也可以是linear或者exp
"gauss": {
"price": {
"origin": "0",
"scale": "20"
}
}位置定义为:
# 此衰减函数也可以是linear或者exp
"gauss": {
"location": {
"origin": "0,0",
"scale": "2km"
}
}假设您要将这两个函数乘以原始分数,则请求将如下所示:
GET /hotel/_search
{
"query": {
"function_score": {
"functions": [
{
"gauss": {
"price": {
"origin": "0",
"scale": "20"
}
}
},
{
"gauss": {
"location": {
"origin": "0, 0",
"scale": "2km"
}
}
}
],
"query": {
"match_all": {}
},
"score_mode": "multiply"
}
}
}接下来,我们展示三个衰减函数中的每一个的计算分数如何。
正常衰减,gauss
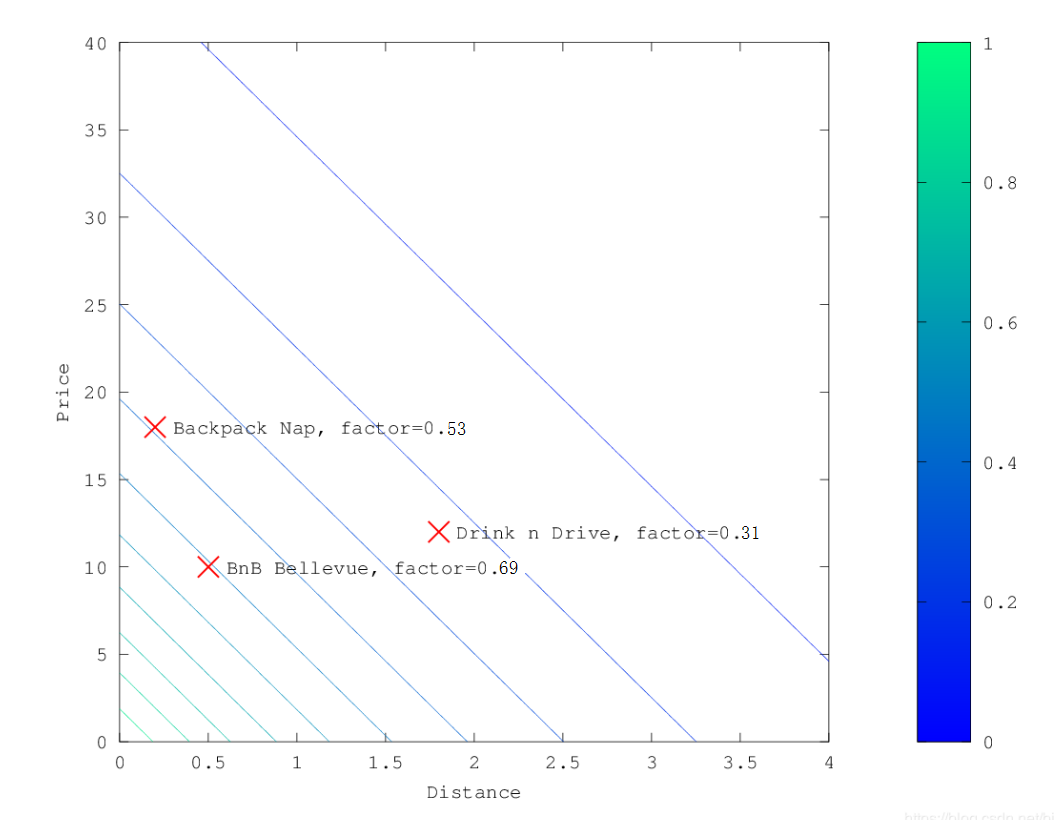
在上面的示例中,选择gauss作为衰减函数时,乘数的轮廓和曲面图如下所示:
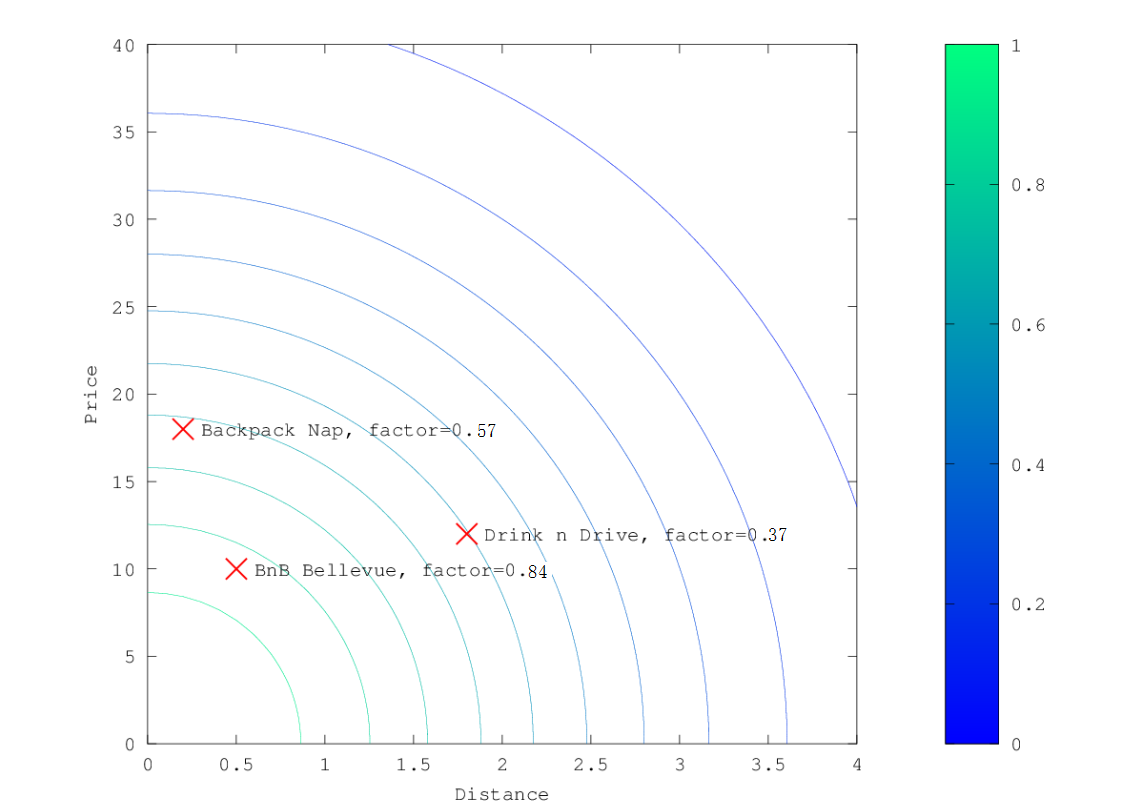
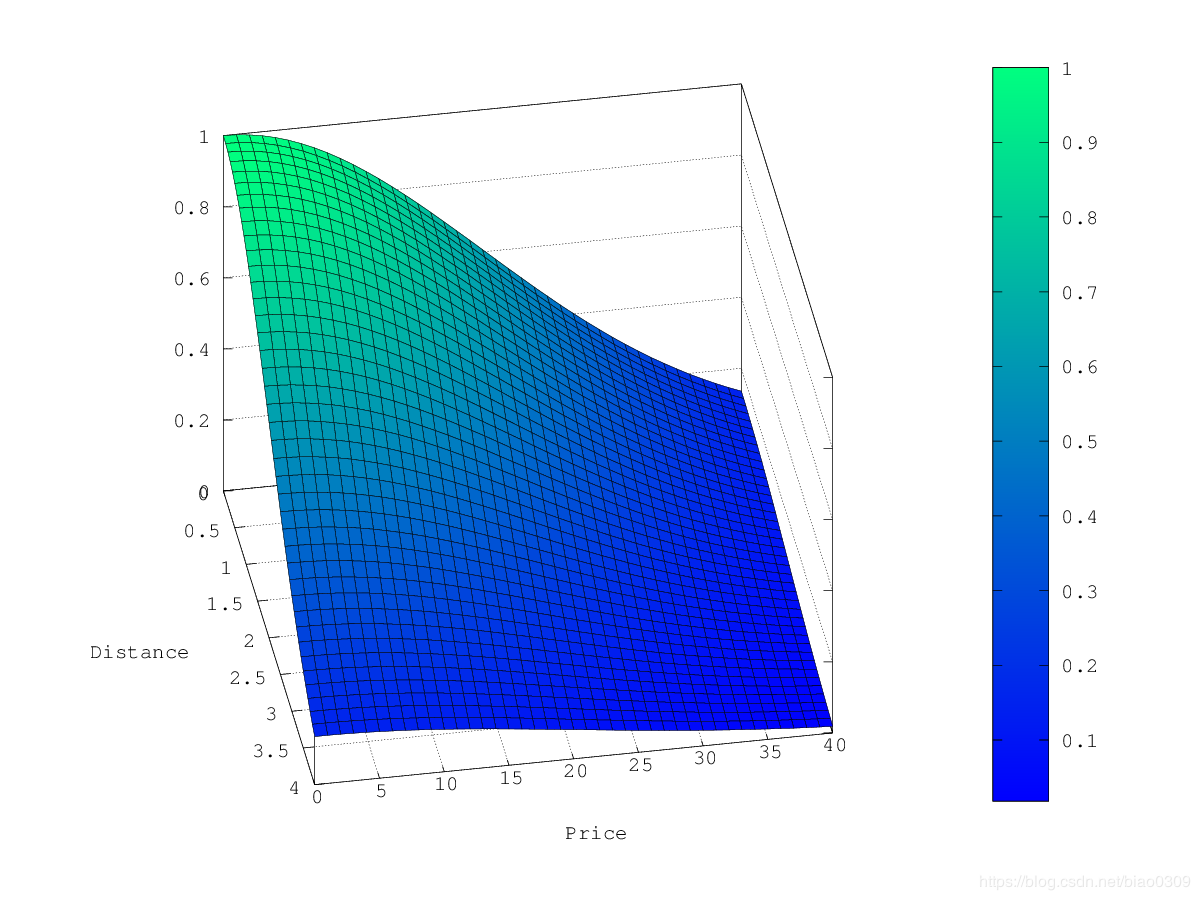
假设您的原始搜索结果匹配三家酒店:
- Backpack Nap
- Drink n Drive
- BnB Bellevue
"Backback Nap"距离您定义的位置很近(近2公里),而且价格也不便宜(约13欧元),因此它的系数低至0.37。 "BnB Bellevue"和"Backback Nap"都非常接近定义的位置,但"BnB Bellevue"更便宜,因此它的乘数为0.84,而"Backback Nap"的值为0.57。
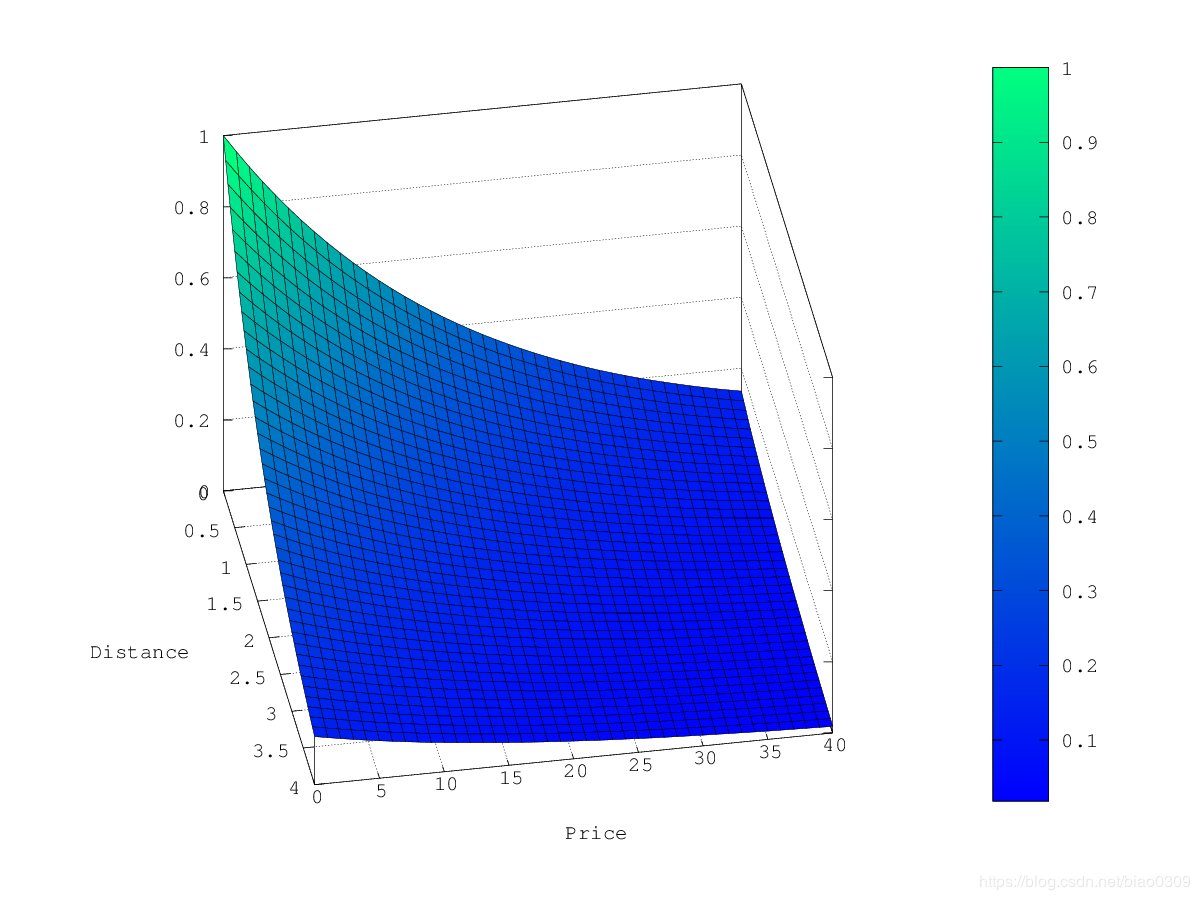
指数衰减,exp
在上面的示例中,选择exp作为衰减函数时,乘数的轮廓和曲面图如下所示:
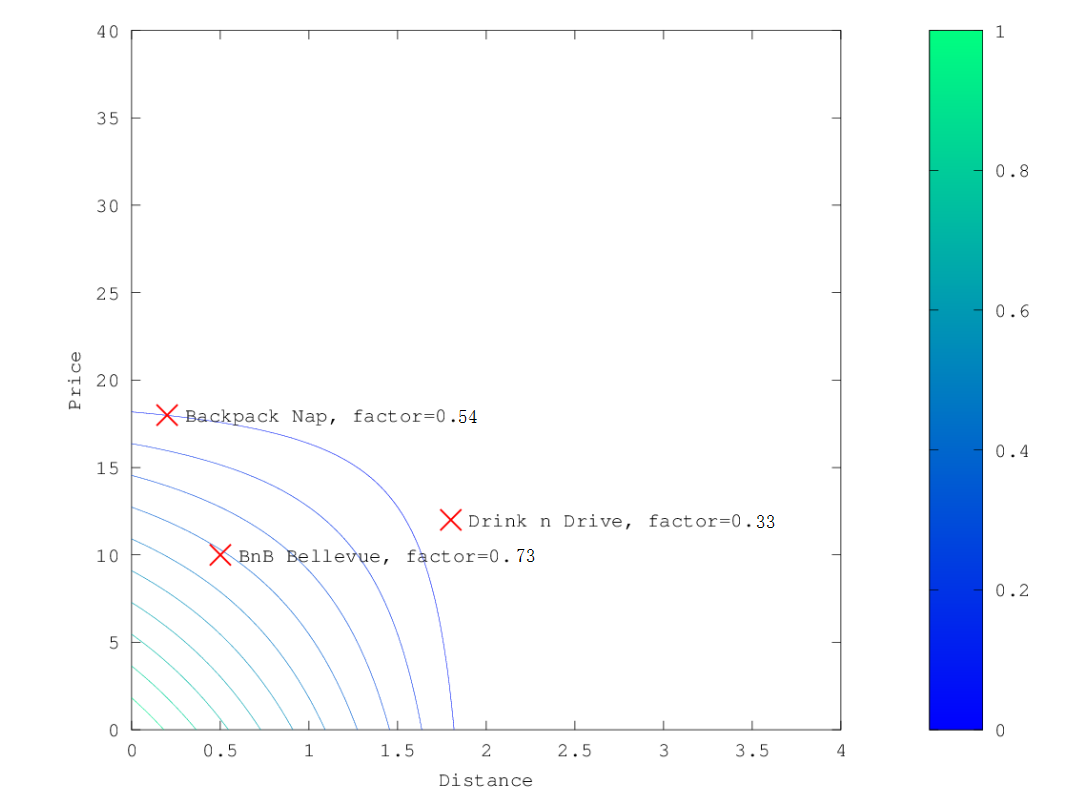
线性衰减,linear
在上面的示例中,选择线性作为衰减函数时,乘数的轮廓和曲面图如下所示:
如果缺少字段怎么办
如果文档中缺少数字字段,该函数将返回1。
bulk操作的api json格式与底层性能优化的关系
之前我们看过bulk的json格式很奇葩,不能换行,两行为一组(除删除外),如下:
{"action" : {"metadata"}}
{"data"}举例:
POST /_bulk
{ "delete": { "_index": "book", "_id": "1" }}
{ "create": { "_index": "book", "_id": "5" }}
{ "name": "test14","price":100.99 }
{ "update": { "_index": "book", "_id": "2"} }
{ "doc" : {"name" : "test"} }而不是下面的形式:
[{
"action": {
{
"metadata"
}
},
"data": {
}
}]bulk中的每个操作都可能要转发到不同node的shard上执行。
如果采用比较良好的json数组格式
首先,整个可读性非常棒,读起来很爽,ES拿到那种标准格式的JSON串以后,要按照下述流程去进行处理:
- 将JSON数组解析为JSONArray对象,这个时候,整个数据,就会在内存中出现一份一模一样的拷贝,一份数据是JSON文本,一份数据是JSONArray对象
- 解析JSON数组里的每个JSON,对每个请求中的document进行路由
- 为路由到同一个
shard上的多个请求,创建一个请求数组 - 将这个请求数组序列化
- 将序列化后的请求数组发送到对应的节点上去
现在这种丑陋两行格式的JSON
- 不用将其转换为JSON对象,不会出现内存中的相同数据的拷贝,直接按照换行符切割JSON
- 对每两个一组的JSON,读取META,进行document路由
- 直接将对应的JSON发送到
node上去
两种格式对比,为什么ES选择丑陋的格式
优雅格式
耗费更多的内存,更多的JVM GC开销。我们之前提到过bulk size最佳大小的问题,一般建议说在几千条那样,然后大小在10MB左右,所以说,可怕的事情来了,假设说现在100个bulk请求发送到了一个节点上去,然后每个请求是10MB,100个请求就是1000MB=1GB。然后每个请求的json都copy一份为JSONArray对象,此时内存中的占用就会翻倍,就会占用2GB内存,甚至还不止,因为弄成JSONArray后,还可能会多搞一些其他的数据结构,2GB+的内存占用。
占用更多的内存可能就会积压其他请求的内存使用量,比如说最重要的搜索请求,分析请求,等等,此时就可能会导致其他请求的性能急速下降另外的话,占用内存更多,就会导致ES的java虚拟机的垃圾回收次数更多,更频繁,每次要回收的垃圾对象更多,耗费的时间更多,导致ES的java虚拟机停止工作线程的时间更多。
丑陋的JSON格式
最大的优势在于,不需要将JSON数组解析为一个JSONArray对象,形成一份大数据的拷贝,浪费内存空间,尽可能的保证性能。
深度分页问题和解决方案
深度分页问题
ES默认采用的分页方式是from+ size的形式,类似于MySQL的分页limit。当请求数据量比较大时,Elasticsearch会对分页做出限制,因为此时性能消耗会很大。举个例子,一个索引分10个shard,然后,一个搜索请求,from=990,size=10,这时候,会带来严重的性能问题:
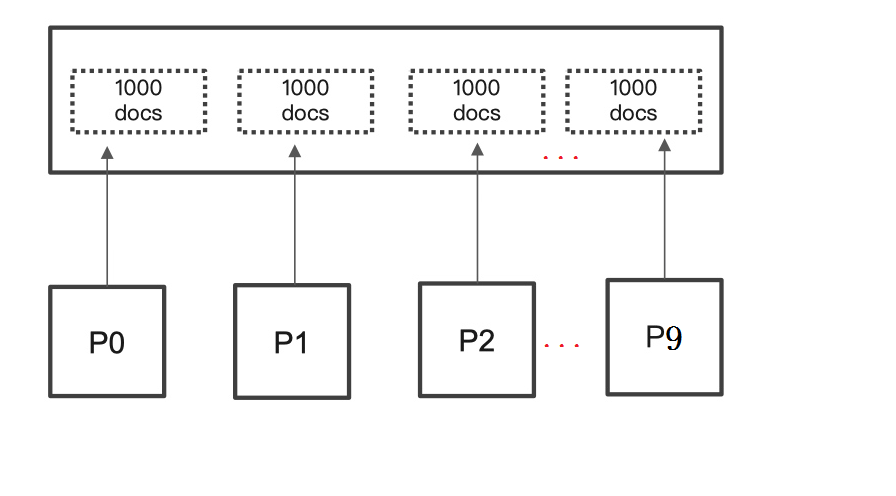
CPU、内存和IO消耗容易理解,网络带宽问题稍难理解一点。在query阶段,每个shard需要返回1000条数据给 coordinating node,而coordinating node需要接收 10*1000 条数据,即使每条数据只 _doc _id和_score,这数据量也很大了,而且,这才一个查询请求,那如果再乘以100呢?
ES中有个设置index.max_result_window,默认是10000条数据,如果分页的数据超过第1万条,就拒绝返回结果了。如果你觉得自己的集群还算可以,可以适当的放大这个参数,比如100万。
我们意识到,有时这种深度分页的请求并不合理,因为我们是很少人为的看很后面的请求的,在很多的业务场景中,都直接限制分页,比如只能看前100页。
不过,这种深度分页确实存在,比如有1千万粉丝的微信大V,要给所有粉丝群发消息,或者给某省粉丝群发,这时候就需要取得所有符合条件的粉丝,而最容易想到的就是利用from + size来实现,但这是不现实的,我们需要使用下面的解决方案。
深度分页解决方案
利用scroll遍历方式
scroll分为初始化和遍历两步,初始化时将所有符合搜索条件的搜索结果缓存起来,可以想象成快照,在遍历时,从这个快照里取数据,也就是说,在初始化后对索引插入、删除、更新数据都不会影响遍历结果。因此,scroll 并不适合用来做实时搜索,而更适用于后台批处理任务,比如群发。
初始化:
POST /book/_search?scroll=1m&size=2
{
"query": { "match_all": {}}
}初始化时需要像普通search一样,指明index和type(当然,search是可以不指明index和type的),然后,加上参数 scroll,表示暂存搜索结果的时间,其它就像一个普通的search请求一样。
初始化返回一个scroll_id,scroll_id用来下次取数据用。
遍历:
GET /_search/scroll
{
"scroll": "1m",
"scroll_id" : "步骤1中查询出来的值"
}这里的scroll_id即上一次遍历取回的_scroll_id或者是初始化返回的_scroll_id,同样的,需要带scroll参数。 重复这一步骤,直到返回的数据为空,即遍历完成。注意,每次都要传参数scroll,刷新搜索结果的缓存时间。另外,不需要指定 index 和 type。设置scroll的时候,需要使搜索结果缓存到下一次遍历完成,同时,也不能太长,毕竟空间有限。
search after方式
满足实时获取下一页的文档信息。search_after分页的方式是根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改,这些变更也会实时的反映到游标上,这种方式是在ES-5.X之后才提供的。为了找到每一页最后一条数据,每个文档的排序字段必须有一个全局唯一值使用_id就可以了。
GET /book/_search
{
"query":{
"match_all": {}
},
"size":2,
"sort":[
{
"_id": "desc"
}
]
}GET /book/_search
{
"query":{
"match_all": {}
},
"size":2,
"search_after":[3],
"sort":[
{
"_id": "desc"
}
]
}下一页的数据依赖上一页的最后一条的信息,所以不能跳页。
三种分页方式比较
| 分页方式 | 性能 | 优点 | 缺点 | 场景 |
| from + size | 低 | 灵活性好,实现简单 | 深度分页问题 | 数据量比较小,能容忍深度分页问题 |
| scroll | 中 | 解决了深度分页问题 | 无法反映数据的实时性(快照版本) 维护成本高,需要维护一个scroll_id | 海量数据的导出,需要查询海量结果集的数据 |
| search_after | 高 | 性能最好,不存在深度分页问题,能够反映数据的实时变更 | 实现连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结 | 海量数据的分页 |
以上就本文的全部内容了。欢迎小伙伴们积极留言交流~~~

文章评论